Publications
2024
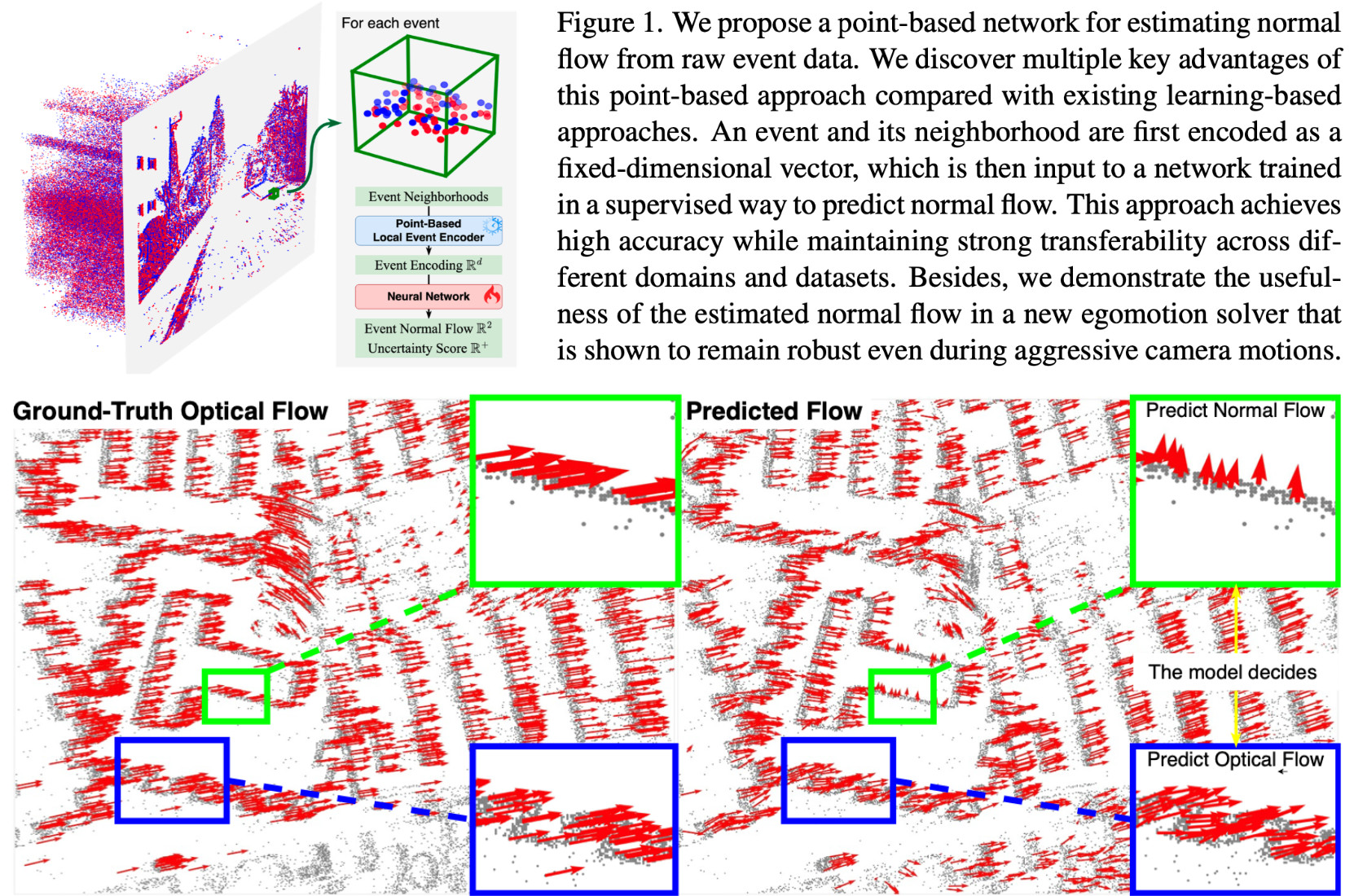
We propose a supervised point-based method for normal flow estimation per-event resulting in temporally and spatially sharp predictions. We introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.

We tackle the problem of estimating 3D contact forces using vision-based tactile sensors. In particular, our goal is to estimate contact forces over a large range (up to 15 N) on any objects while generalizing across different vision-based tactile sensors.

We present a Perception-Action API that consists of VLMs and LLMs as backbones, together with a set of robot control functions. When prompted with this API and a natural language query, an LLM generates a program to actively identify attributes given an input image.
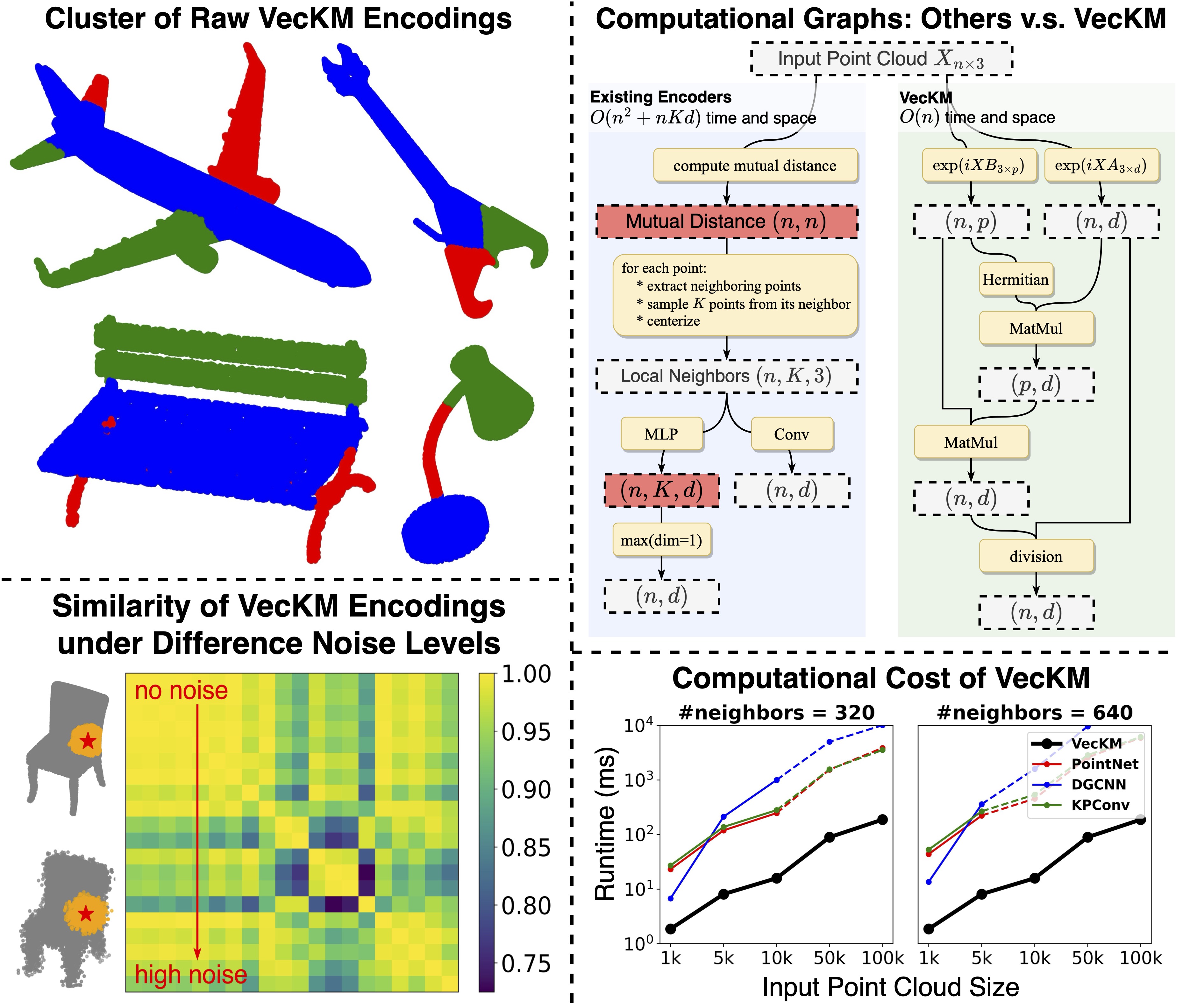
We propose VecKM, a highly efficient local point cloud encoder. VecKM is the first successful attempt to reduce the computation and memory costs from O(n^2+nKd) to O(nd) by sacrificing a marginal factor, where n is the size of the point cloud and K is neighborhood size. The efficiency is primarily due to VecKM's unique factorizable property that eliminates the need of explicitly grouping points into neighborhoods.

We present Cook2LTL, a system that translates instruction steps from an arbitrary cooking recipe found on the internet to a set of LTL formulae, grounding high-level cooking actions to a set of primitive actions that are executable by a manipulator in a kitchen environment. Cook2LTL makes use of a caching scheme that dynamically builds a queryable action library at runtime.

We present AcTExplore, an active tactile exploration method driven by reinforcement learning for object reconstruction at scales that automatically explores the object surfaces in a limited number of steps. Through sufficient exploration, our algorithm incrementally collects tactile data and reconstructs 3D shapes of the objects, which can serve as a representation for higher-level downstream tasks.
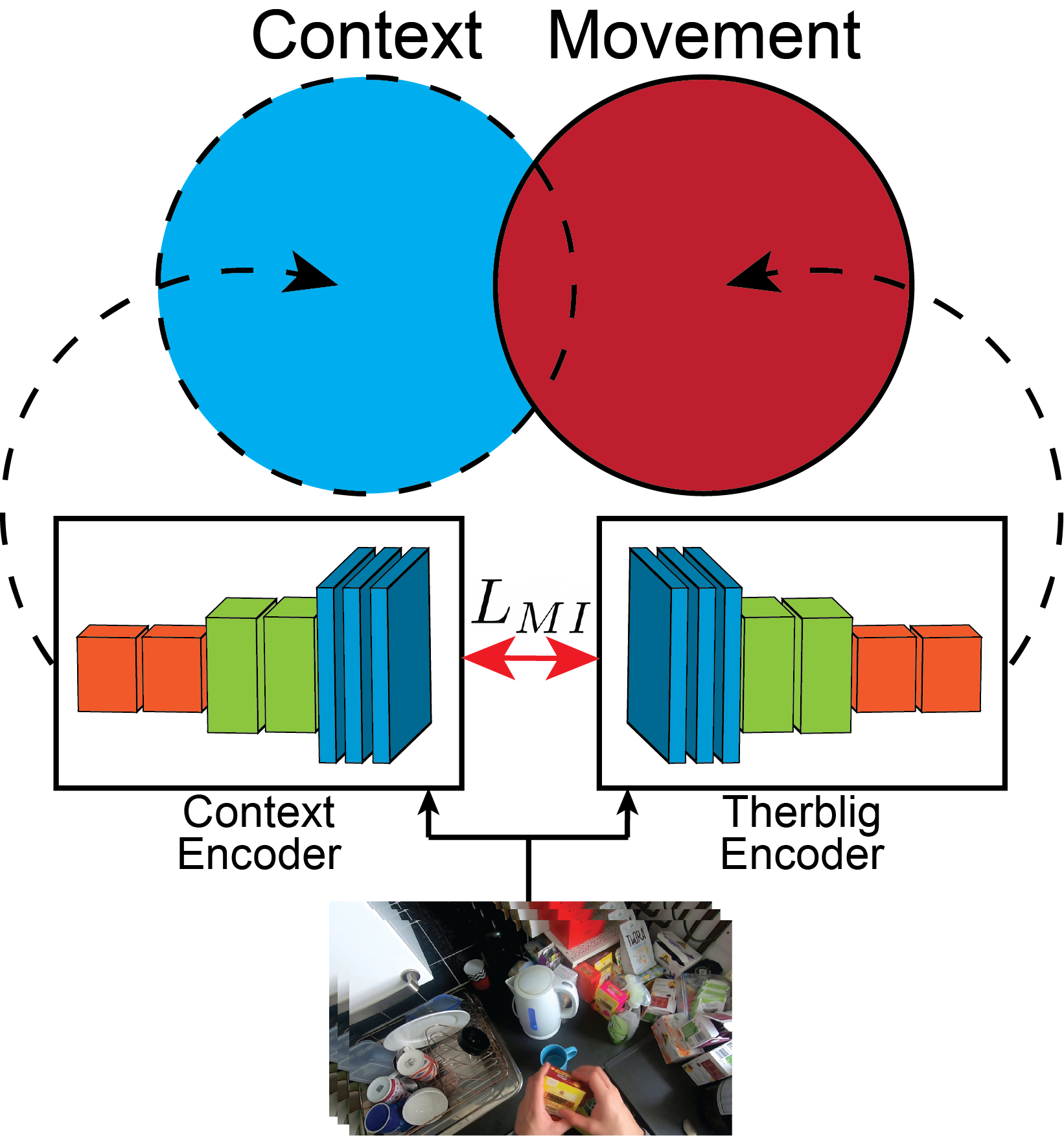
Motivated by Goldman's Theory of Human Action - a framework in which action decomposes into 1) base physical movements, and 2) the context in which they occur - we propose a novel learning formulation for motion and context, where context is derived as the complement to motion. More specifically, we model physical movement through the adoption of Therbligs, a set of elemental physical motions centered around object manipulation. Context is modeled through the use of a contrastive mutual information loss that formulates context information as the action information not contained within movement information.
We introduce Hyper-Dimensional Function Encoding (HDFE), which generates a fixed-length vector representation of continuous objects, such as functions, invariant to sample distribution and density. This invariance allows HDFE to consistently encode continuous objects for neural networks without the need for training. It maps objects into an organized embedding space, aiding downstream task training. HDFE is also decodable, enabling neural networks to regress continuous objects via their encodings. Thus, HDFE acts as an interface for processing continuous objects in machine learning tasks like classification and regression.

We introduce UIVNAV, a novel end-to-end underwater navigation solution designed to drive robots over Objects of Interest (OOI) while avoiding obstacles, without relying on localization. UIVNAV uses imitation learning and is inspired by the navigation strategies used by human divers who do not rely on localization.
2023

In this work, we present the world's first olive detection dataset comprised of synthetic and real olive tree images. Experiments are conducted with a mix of synthetically generated and real images, yielding an improvement of up to 66% compared to when only using a small sample of real data.
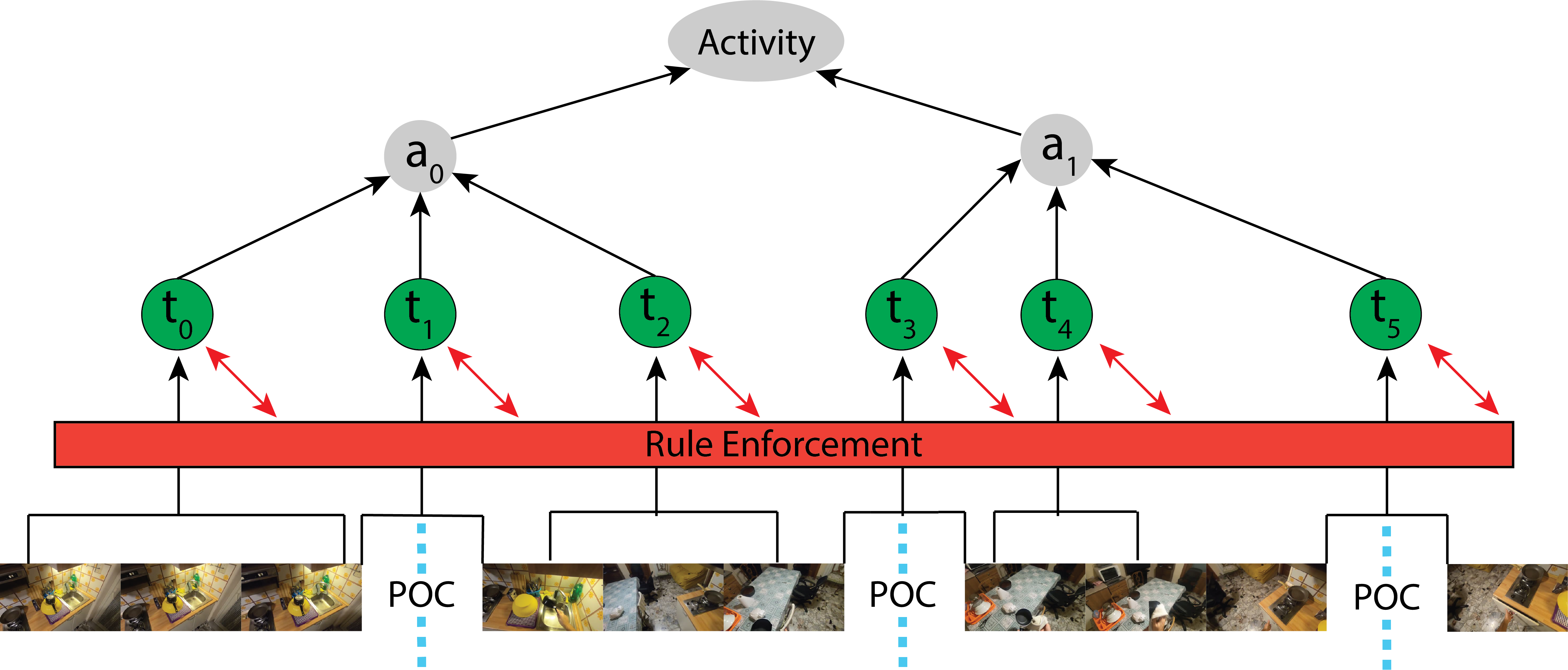
We introduce a rule-based, compositional, and hierarchical modeling of action using Therbligs as our atoms. We broadly demonstrate benefits to adopting Therblig representations through evaluation on the following tasks: action segmentation, action anticipation, and action recognition over CNN and Transformer-based architectures.
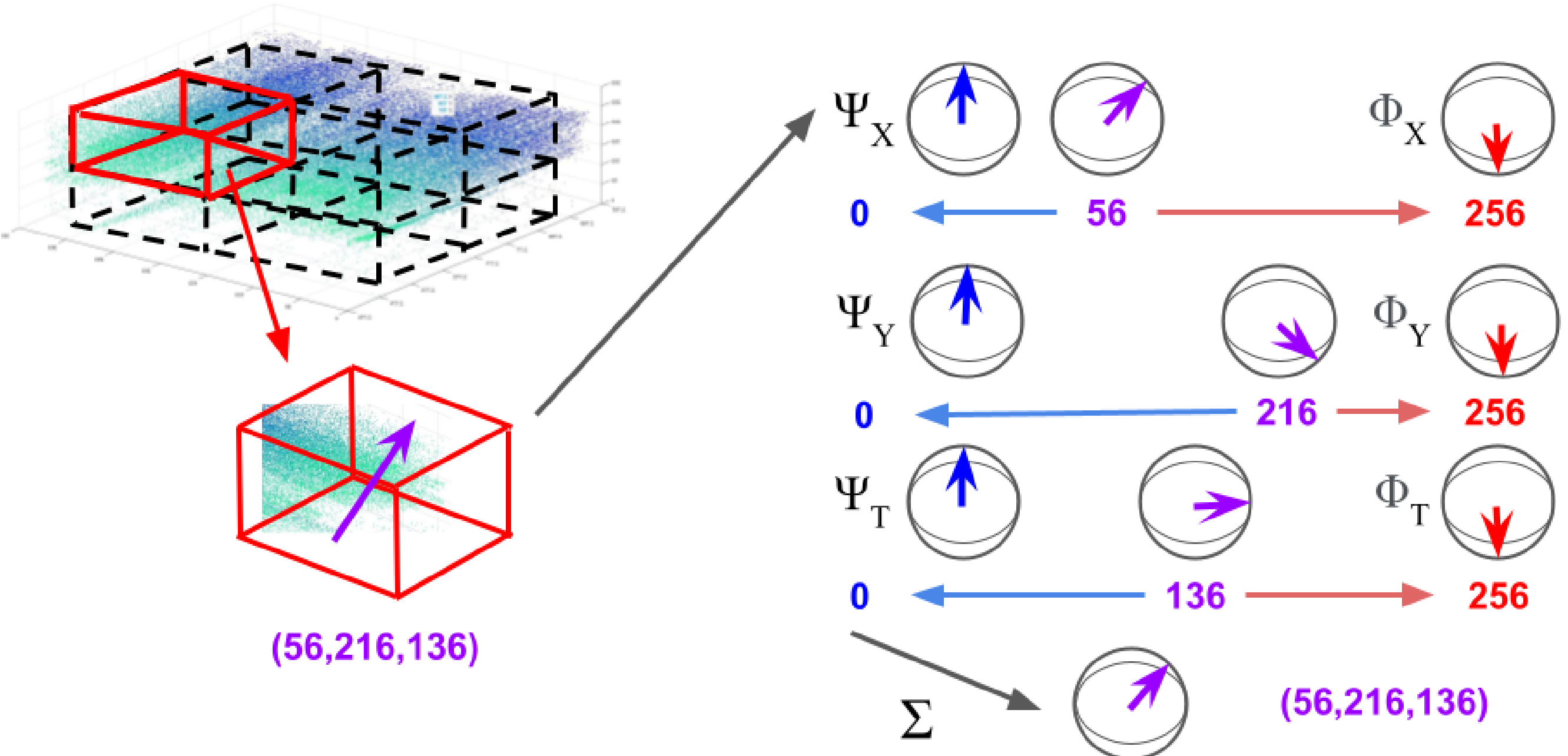
We present a bipolar HD encoding mechanism designed for encoding spatiotemporal data, which captures the contours of DVS-generated time surfaces created by moving objects by fitting to them local surfaces which are individually encoded into HD vectors and bundled into descriptive high-dimensional representations.
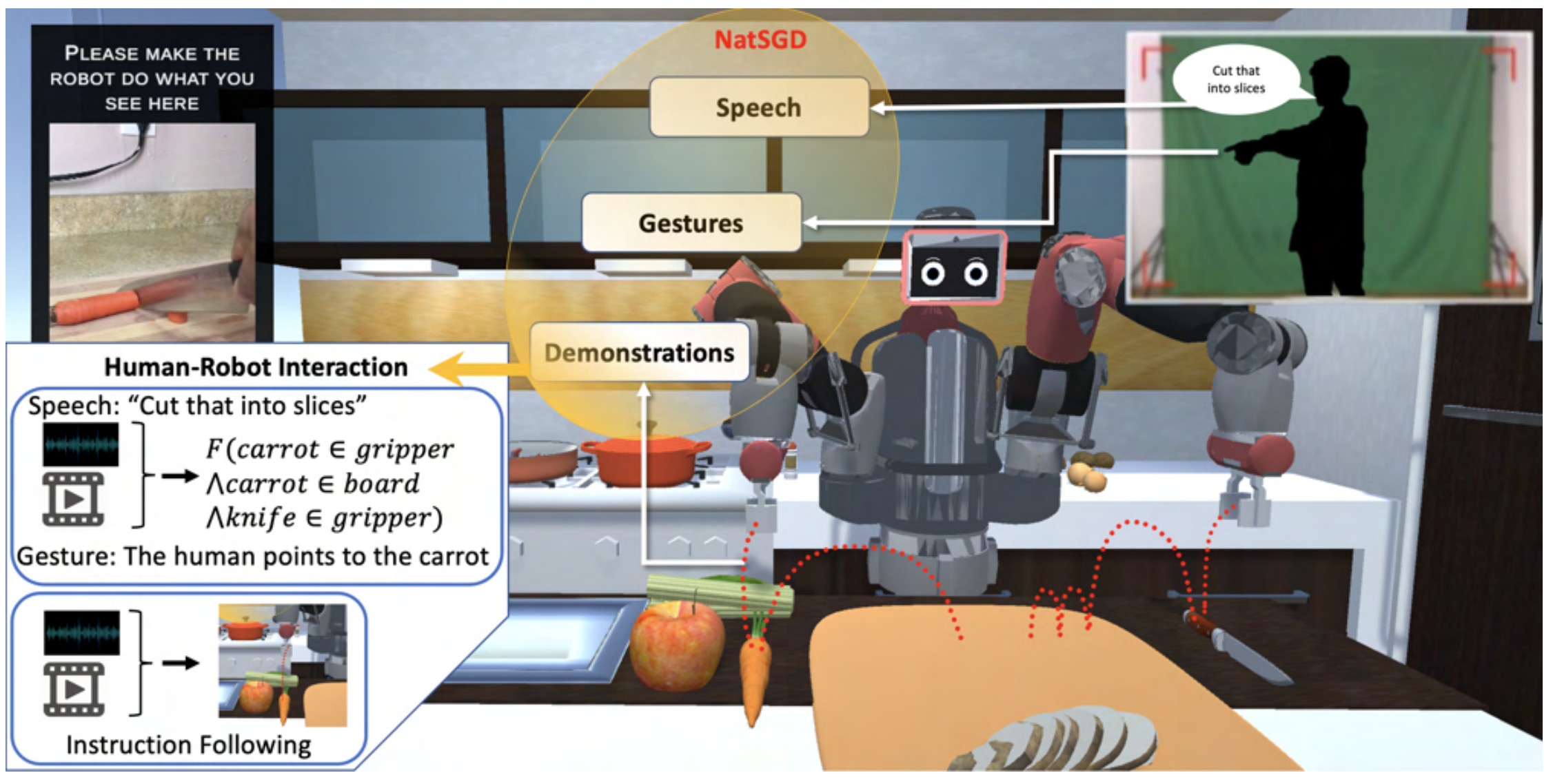
We introduce NatSGD, a multimodal HRI dataset that contains human commands as speech and gestures, along with robot behavior in the form of synchronized demonstrated robot trajectories. Our data enable HRI with Imitation Learning so that robots can learn to work with humans in challenging, real-life domains such as performing complex tasks in the kitchen.
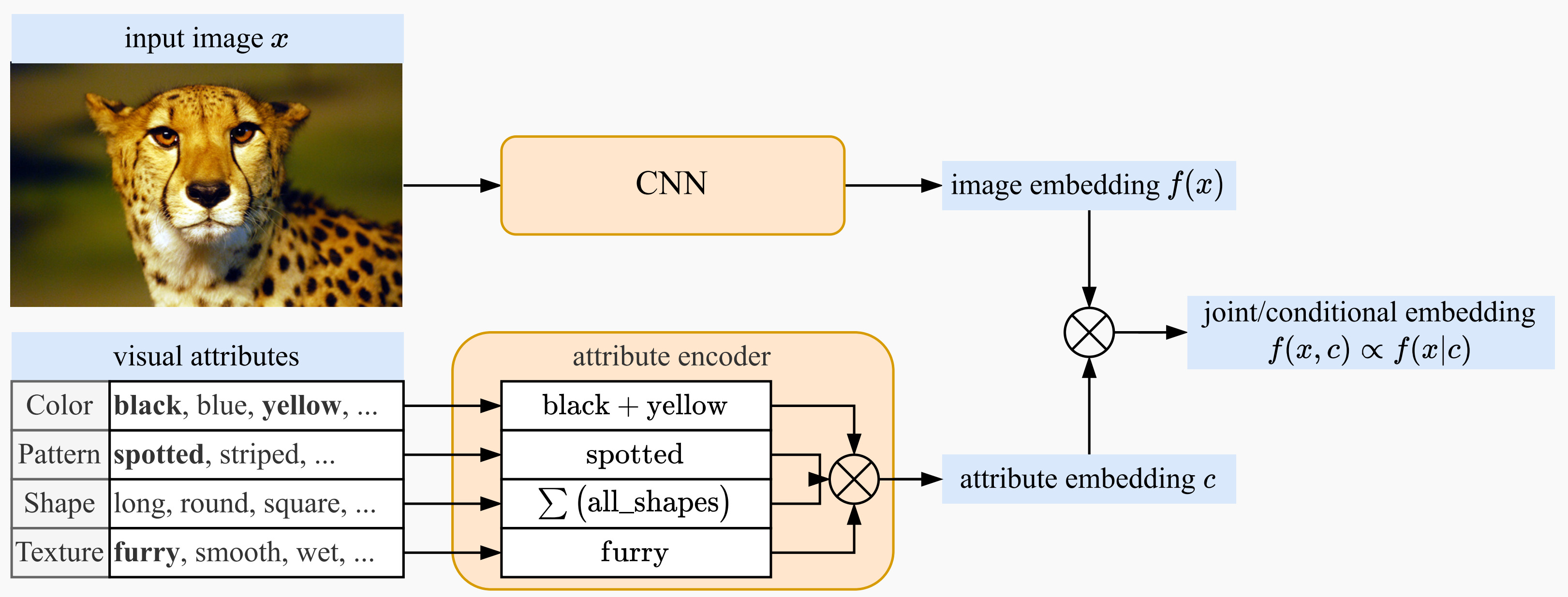
In this work, we propose a novel method of encoding image attributes that combines the attribute encoding and the image encoding. Our novel technique requires very few or even no learnable parameters, but still achieves comparable performance as other data-driven fusion techniques.

In this chapter we outline an action-centric framework which spans multiple time scales and levels of abstraction, producing both action and scene interpretations constrained towards action consistency. At the lower level of the visual hierarchy we detail affordances – object characteristics which afford themselves to different actions. At mid-levels we model individual actions, and at higher levels we model activities through leveraging knowledge and longer term temporal relations.
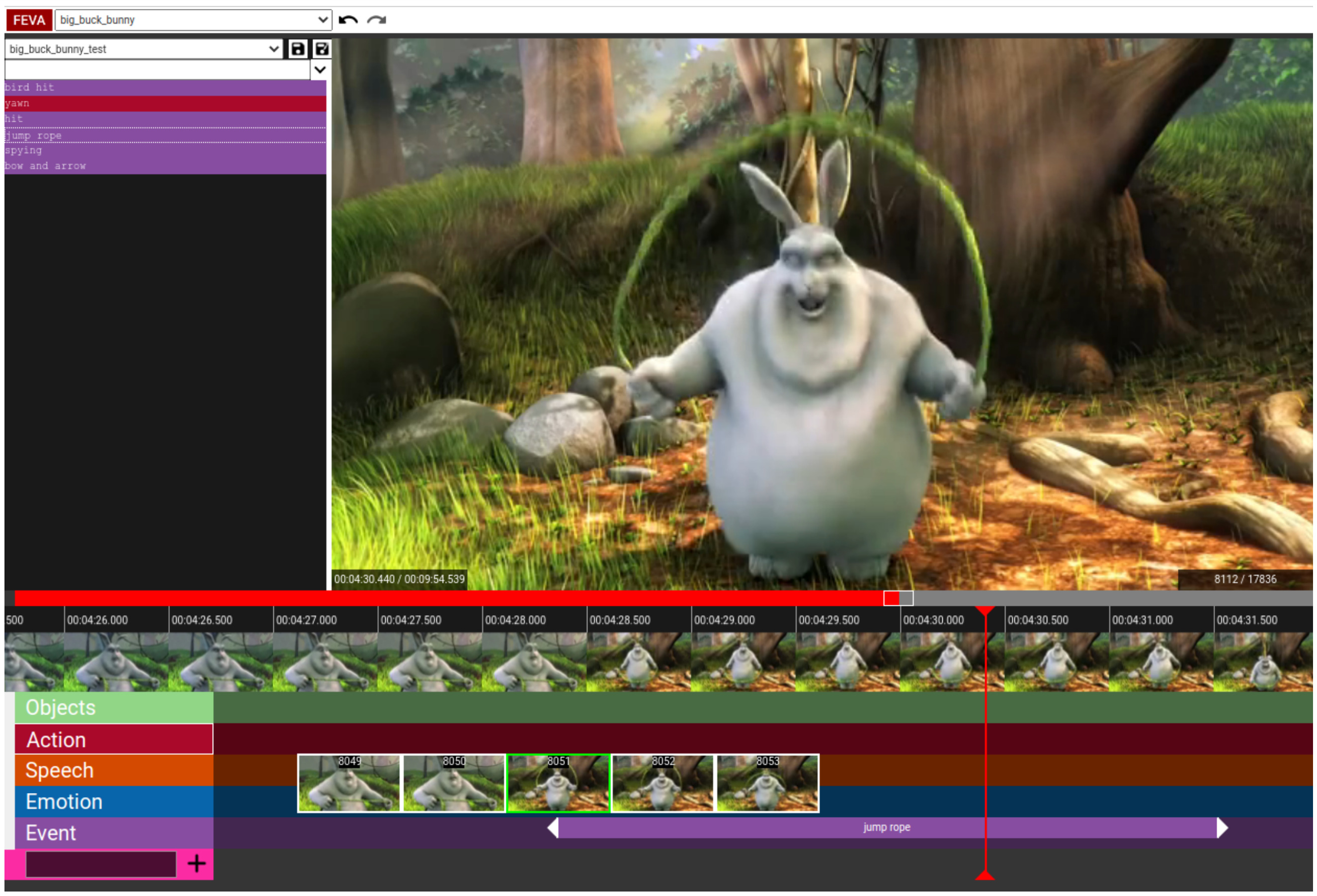
We introduce FEVA, a video annotation tool with streamlined interaction techniques and a dynamic interface that makes labeling tasks easy and fast. FEVA focuses on speed, accuracy, and simplicity to make annotation quick, consistent, and straightforward.

WorldGen is an open source framework to generate countless structured and unstructured 3D photorealistic scenes such as city view, object collection, and object fragmentation along with its rich ground truth annotation data.
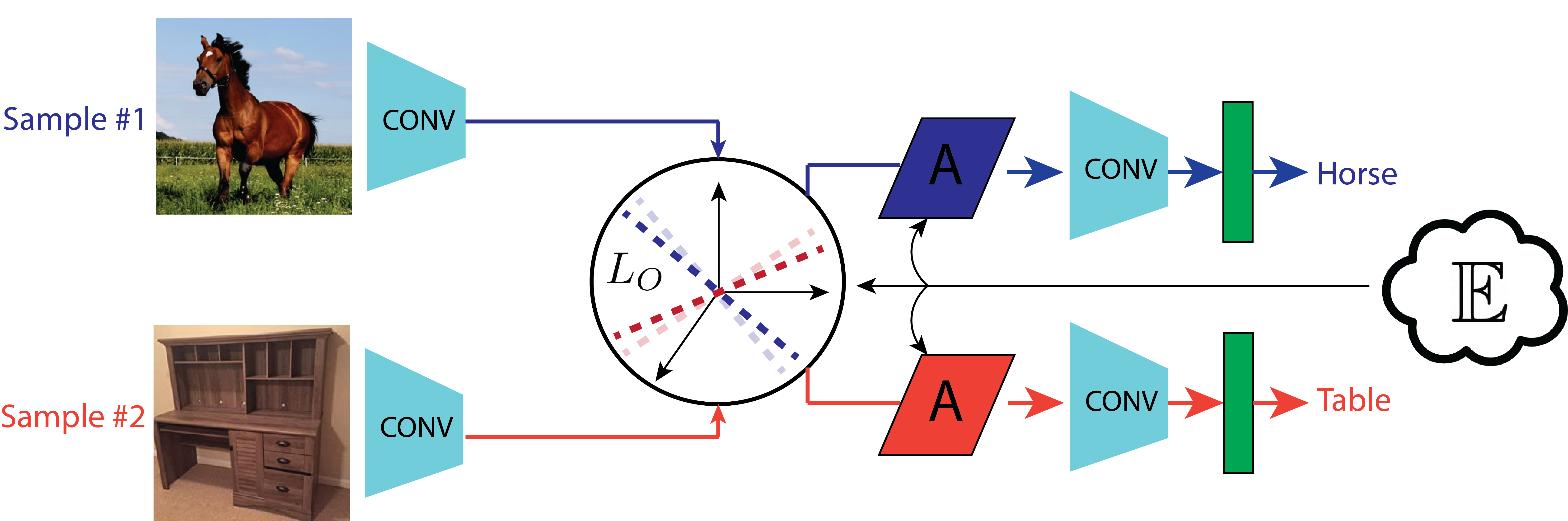
The majority of neural connections in biological vision are top down – we introduce a mechanism in artificial neural networks mirroring this feedback dynamic. High level context, which can be derived from the same network being fed into, is used in modifying features at lower levels towards contextual conformance (in effect providing a high level “hint” to lower levels). This is done through application of affine transformations, trained based on context, over mid-level feature vectors, and is made more manageable through a training term separating context at mid levels.
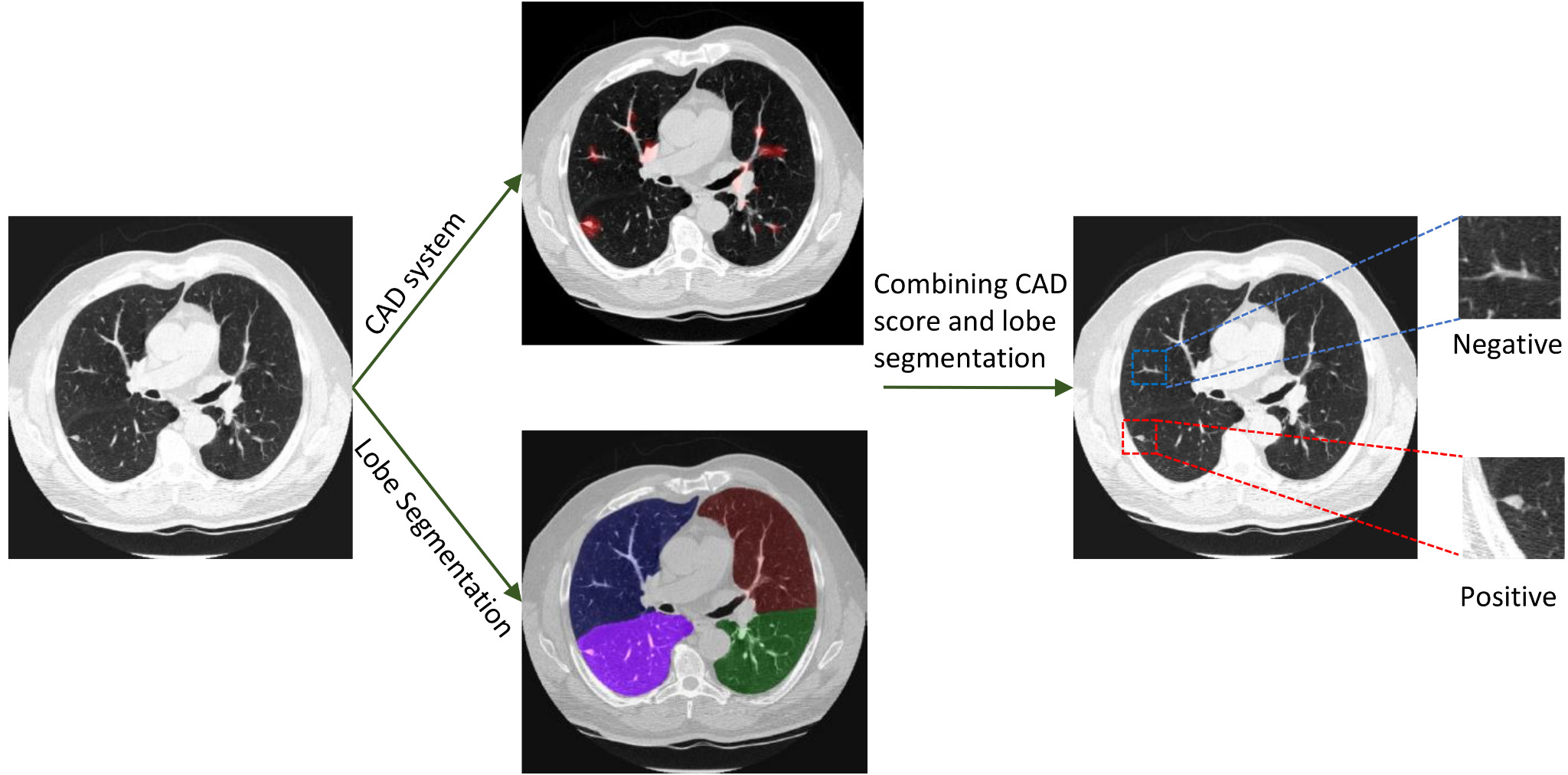
In this study, we propose a cooperative labeling method that allows us to make use of weakly annotated medical imaging data for the training of a machine learning algorithm. As most clinically produced data are weakly-annotated – produced for use by humans rather than machines and lacking information machine learning depends upon – this approach allows us to incorporate a wider range of clinical data and thereby increase the training set size.
2022
We aim at providing a comprehensive overview of the latest advances in Hyperdimensional Computing (HDC).

We present a novel method to mathematically model oysters and render images of oysters in simulation to boost the detection performance with minimal real data.
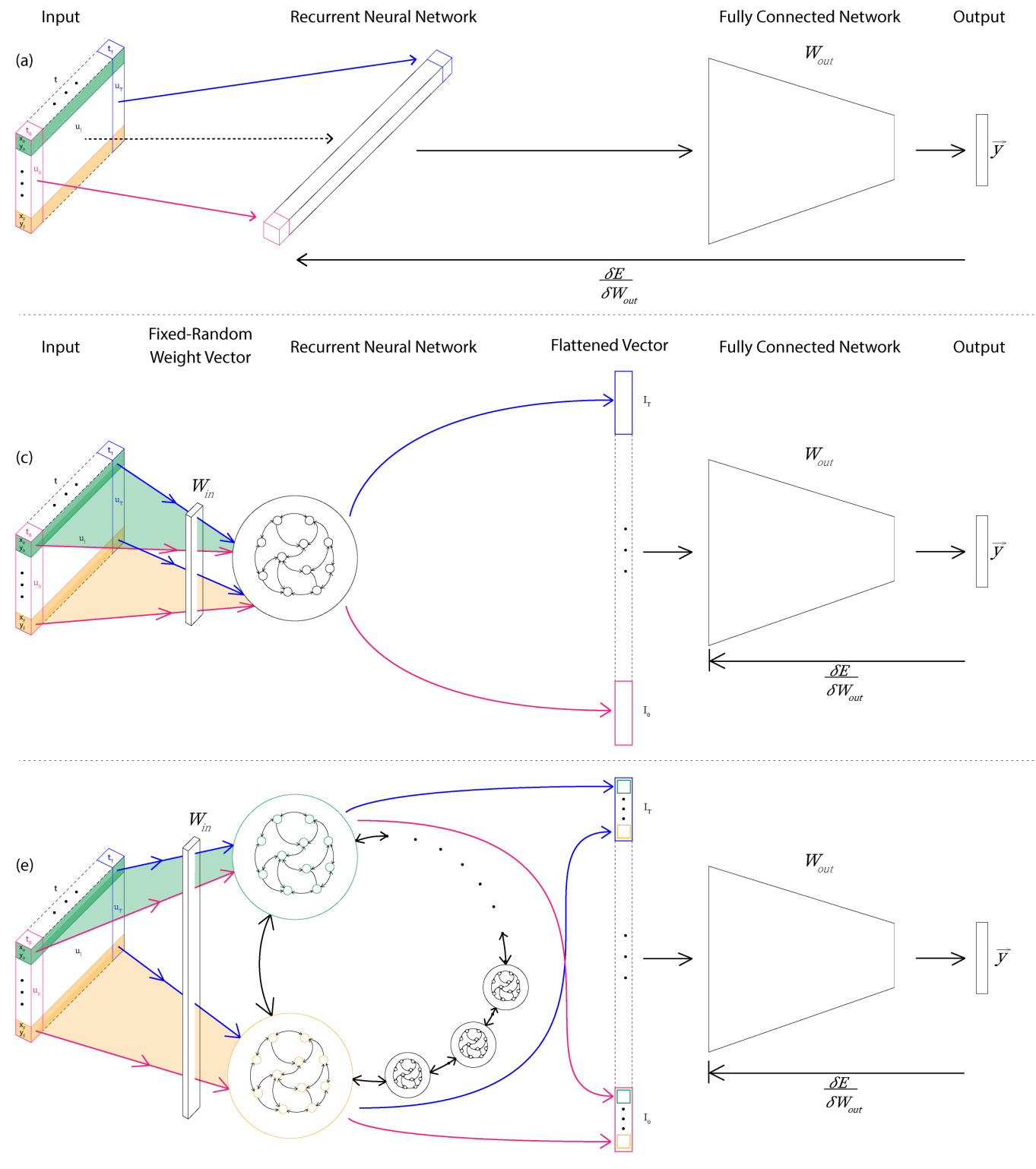
We have developed a novel hybrid network, called Parallelized Deep Readout Echo State Network (PDR-ESN) that combines the deep learning readout with a fast random recurrent component, with multiple ESNs computing in parallel. Our findings suggest that different variants of the PDR-ESN offer various advantages in different task domains, with some performing better in regression and others in classification.
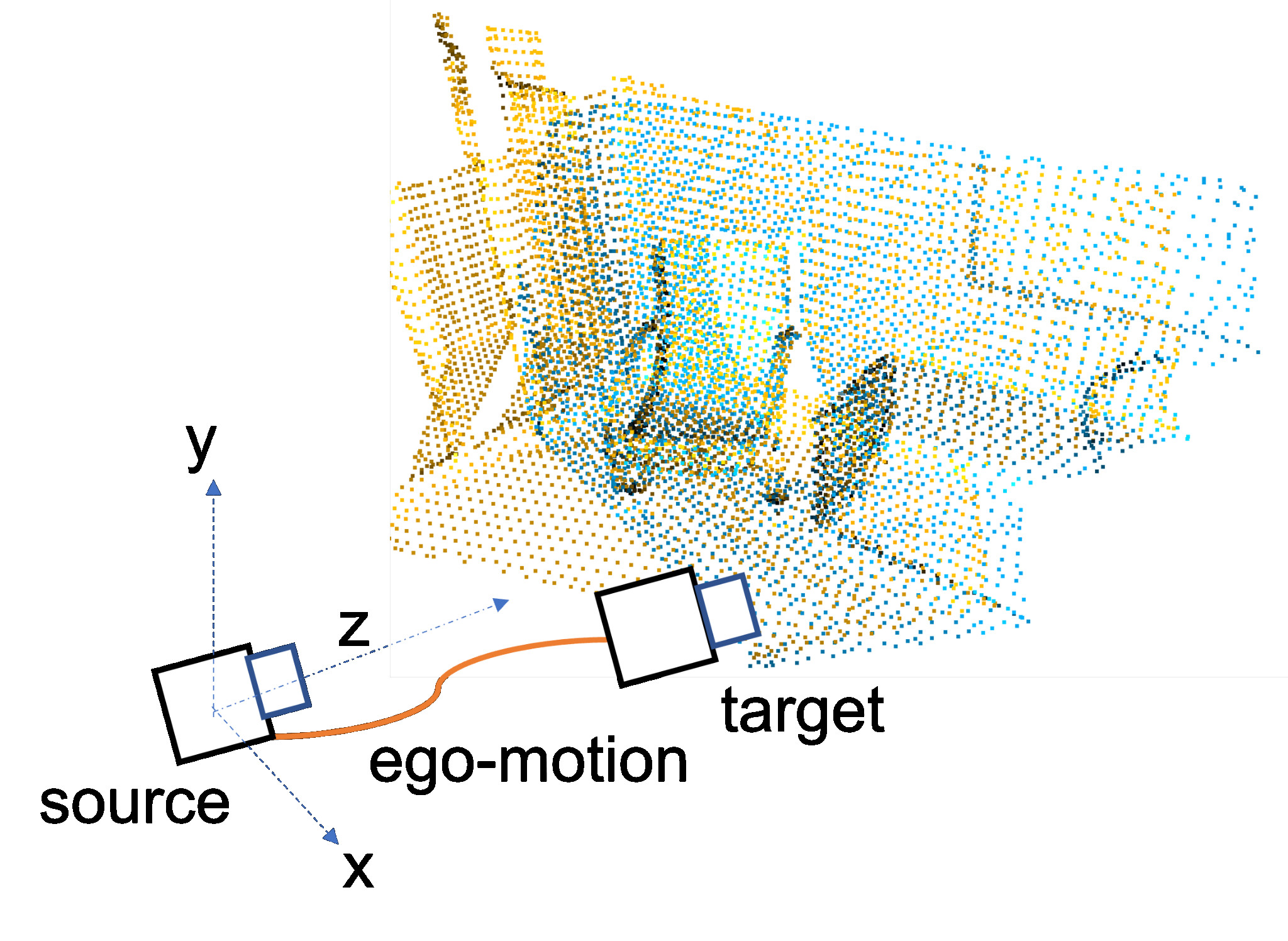
DiffPosNet estimates relative camera pose based on the cheirality (depth positivity) constraint from normal flow computed via a network. This this achieved by formulating the optimization problem as a differentiable cheirality layer, which allows for end-to-end learning of camera pose. Qualitative and quantitative evaluation of the proposed DiffPoseNet’s demonstrate its generalization across datasets and outperforms existing state-of-the-art methods on KITTI, TartanAir, and the TUM-RGBD datasets.

We present a spatio-temporal gradient representation on the data obtained from fluid-based tactile sensors, which is inspired from neuromorphic principles of event based sensing. We present a novel algorithm (GradTac) that converts discrete data points from spatial tactile sensors into spatio-temporal surfaces and tracks tactile contours across these surfaces. We successfully evaluate and demonstrate the efficacy of GradTac on many real-world experiments performed using the Shadow Dexterous Hand, equipped with the BioTac SP sensors.

A new event camera dataset, EVIMO2, is introduced that improves on the popular EVIMO dataset by providing more data, from better cameras, in more complex scenarios.
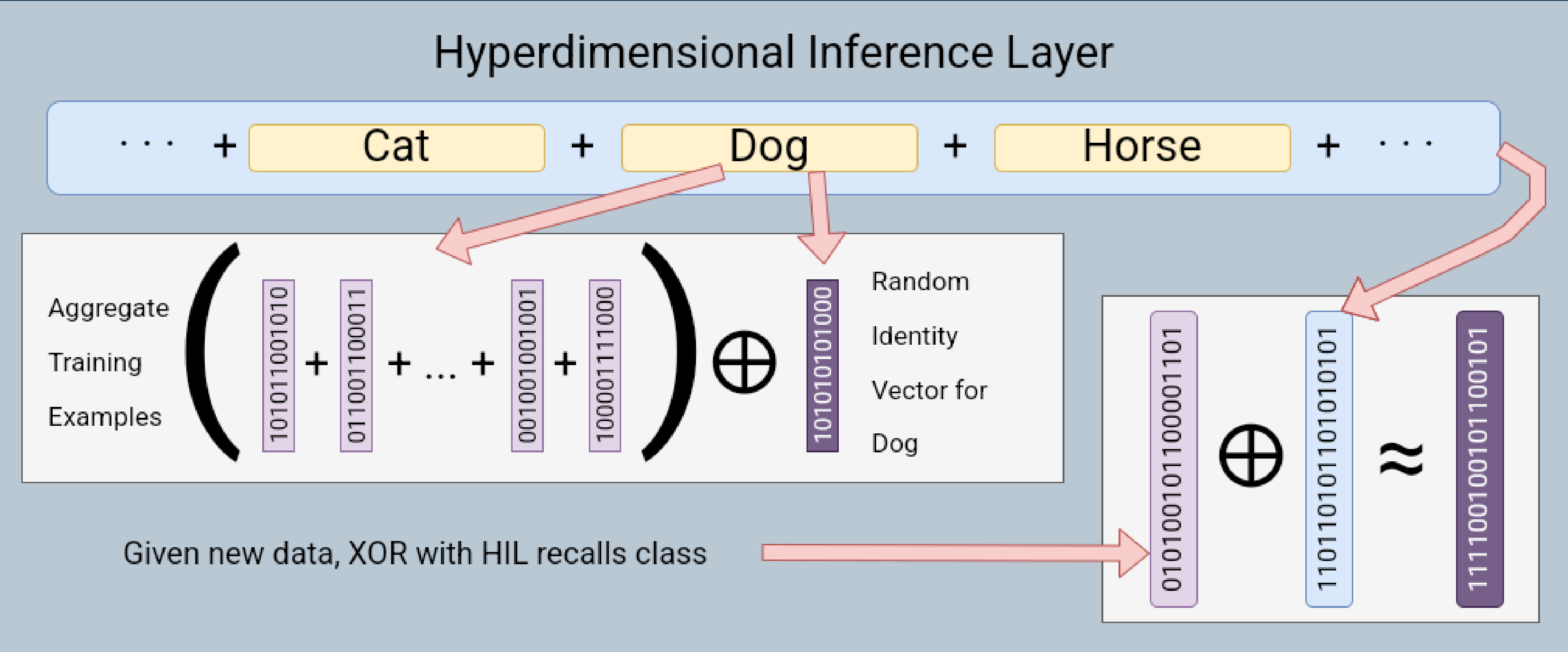
In this paper, we explore the notion of using binary hypervectors to directly encode the final, classifying output signals of neural networks in order to fuse differing networks together at the symbolic level. We find that this outperforms the state of the art, or is on a par with it, while using very little overhead, as hypervector operations are extremely fast and efficient in comparison to the neural networks.
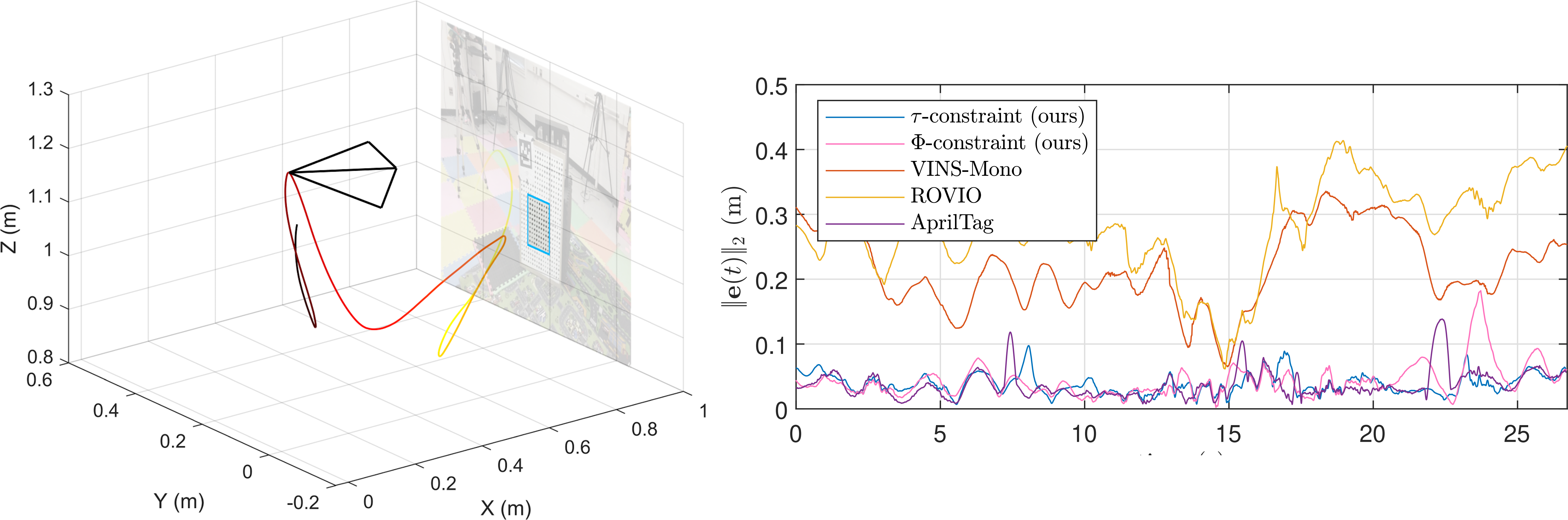
Distance estimation from vision is fundamental for a myriad of robotic applications such as navigation, manipulation and planning. Inspired by the mammal's visual system, which gazes at specific objects, we develop two novel constraints involving time-to-contact, acceleration, and distance that we call the tau-constraint and Phi-constraint which allow an active (moving) camera to estimate depth efficiently and accurately while using only a small portion of the image.
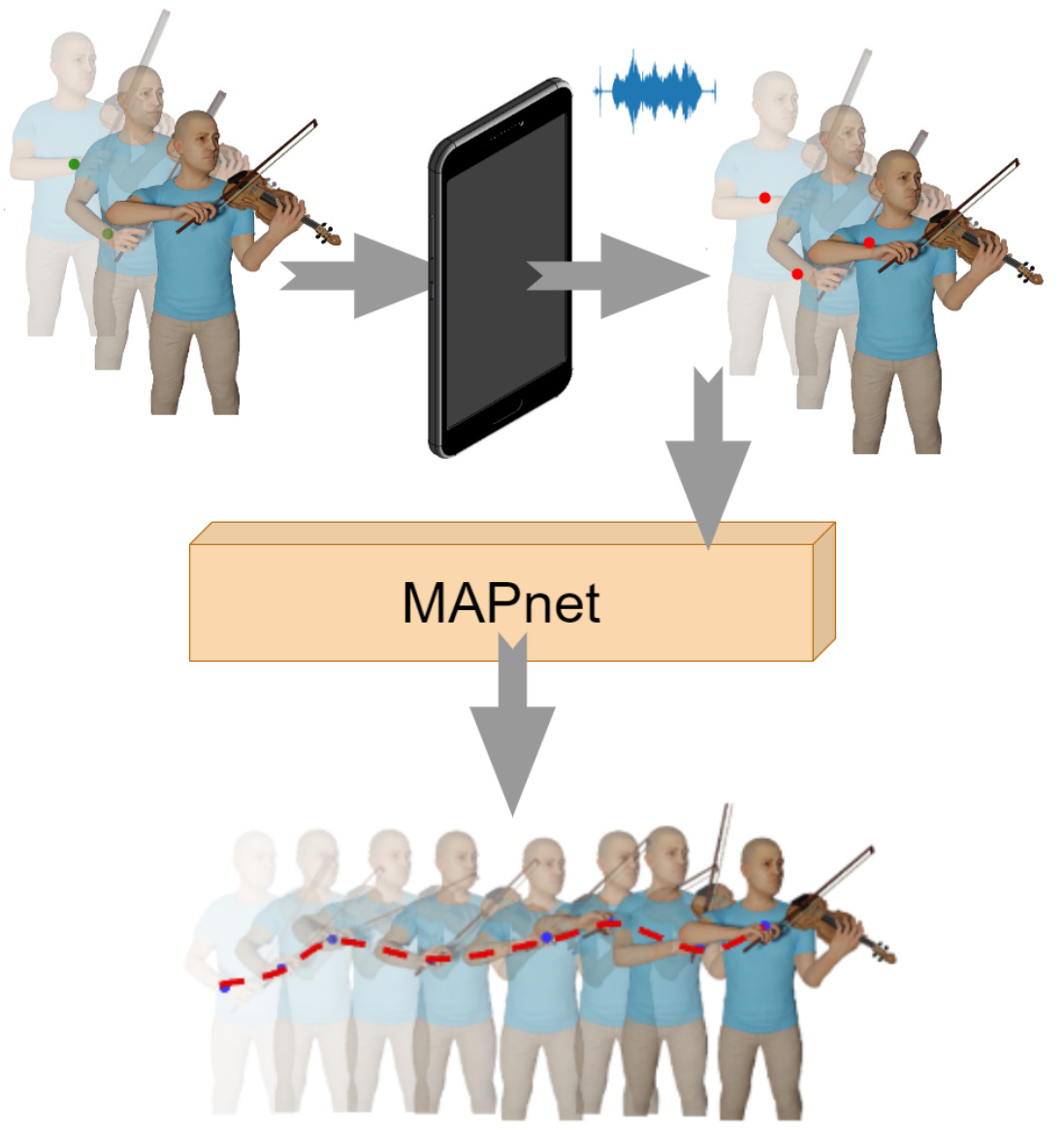
We propose MAPnet (Music Assisted Pose network) for generating a fine grain motion model from sparse input pose sequences but continuous audio. We also open-source MAPdat, a new multi-modal dataset of 3D violin playing motion with music. Experiments on MAPdat suggest multi-modal approaches like ours are a promising direction for tasks previously approached with visual methods only.
2021
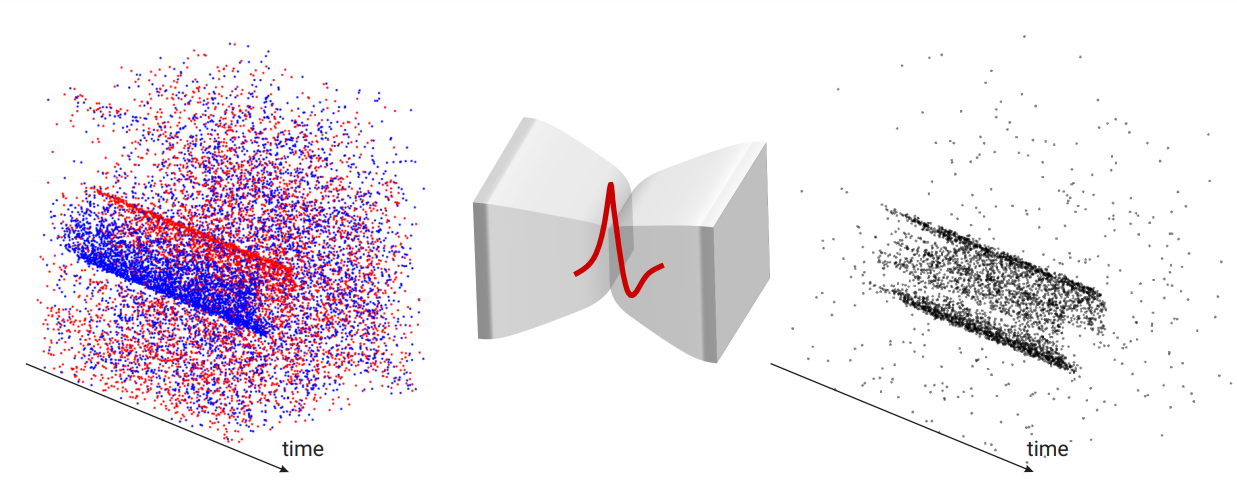
We introduce SpikeMS, the first deep encoder-decoder SNN architecture for the real-world large-scale problem of motion segmentation using the event-based DVS camera as input. To accomplish this, we introduce a novel spatio-temporal loss formulation that includes both spike counts and classification labels in conjunction with the use of new techniques for SNN backpropagation. SpikeMS is capable of incremental predictions, or predictions from smaller amounts of test data than it is trained on. This is invaluable for providing outputs even with partial input data for low-latency applications and those requiring fast predictions.
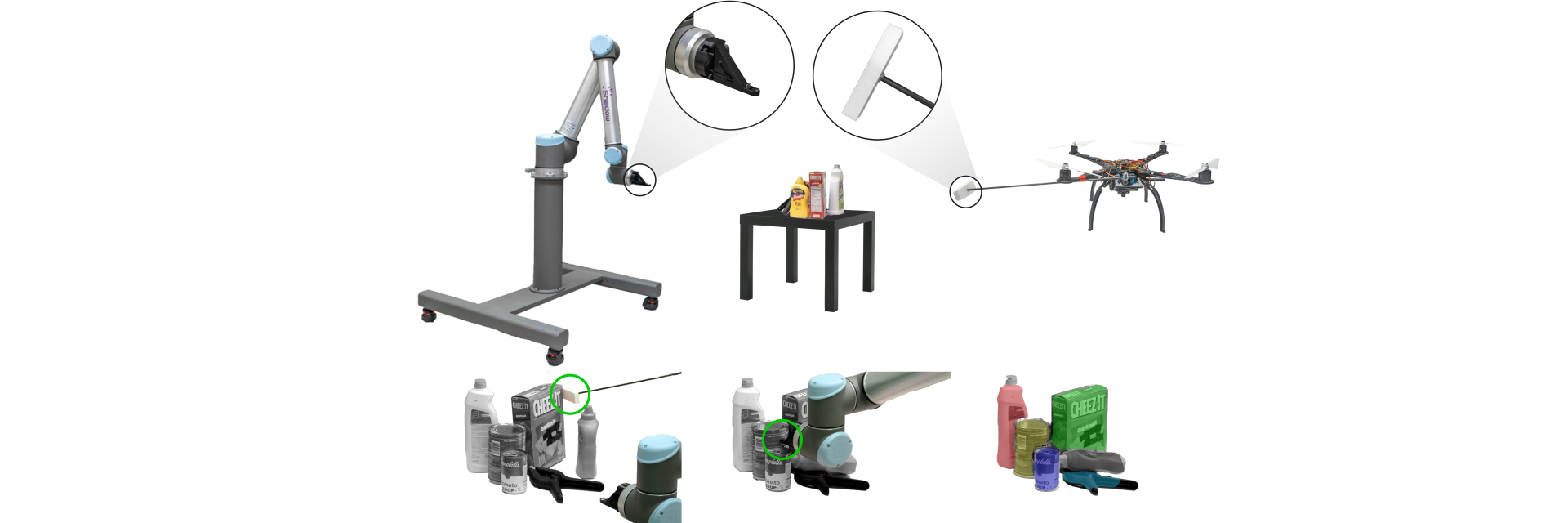
Object segmentation using image frames relies on recognition and pattern matching cues. Instead, We utilize the ‘active’ nature of a robot and its ability to ‘interact’ with the environment to induce additional geometric constraints for segmenting zero-shot samples.

We present a deep learning approach called PRGFlow for obtaining global optical flow and then loosely fuse it with an IMU for full 6-DoF relative pose estimation. It is shown that the method outperforms classical feature matching methods by 2x under noisy data.

We model the geometry of a propeller and use it to generate simulated events which are used to train a deep neural network called EVPropNet to detect propellers from the data of an event camera. EVPropNet directly transfers to the real world without any fine-tuning or retraining. We present two applications of our network: (a) tracking and following an unmarked drone and (b) landing on a near-hover drone.

This work presents our efforts for videography of the Chesapeake bay bottom using an ROV, constructing a database of oysters, implementing Mask R-CNN for detecting oysters, and counting their number in a video by tracking them.

We present an approach for monocular multi-motion segmentation, which combines bottom-up feature tracking and top-down motion compensation into a unified pipeline, which is the first of its kind to our knowledge. Using the events within a time-interval, our method segments the scene into multiple motions by splitting and merging.
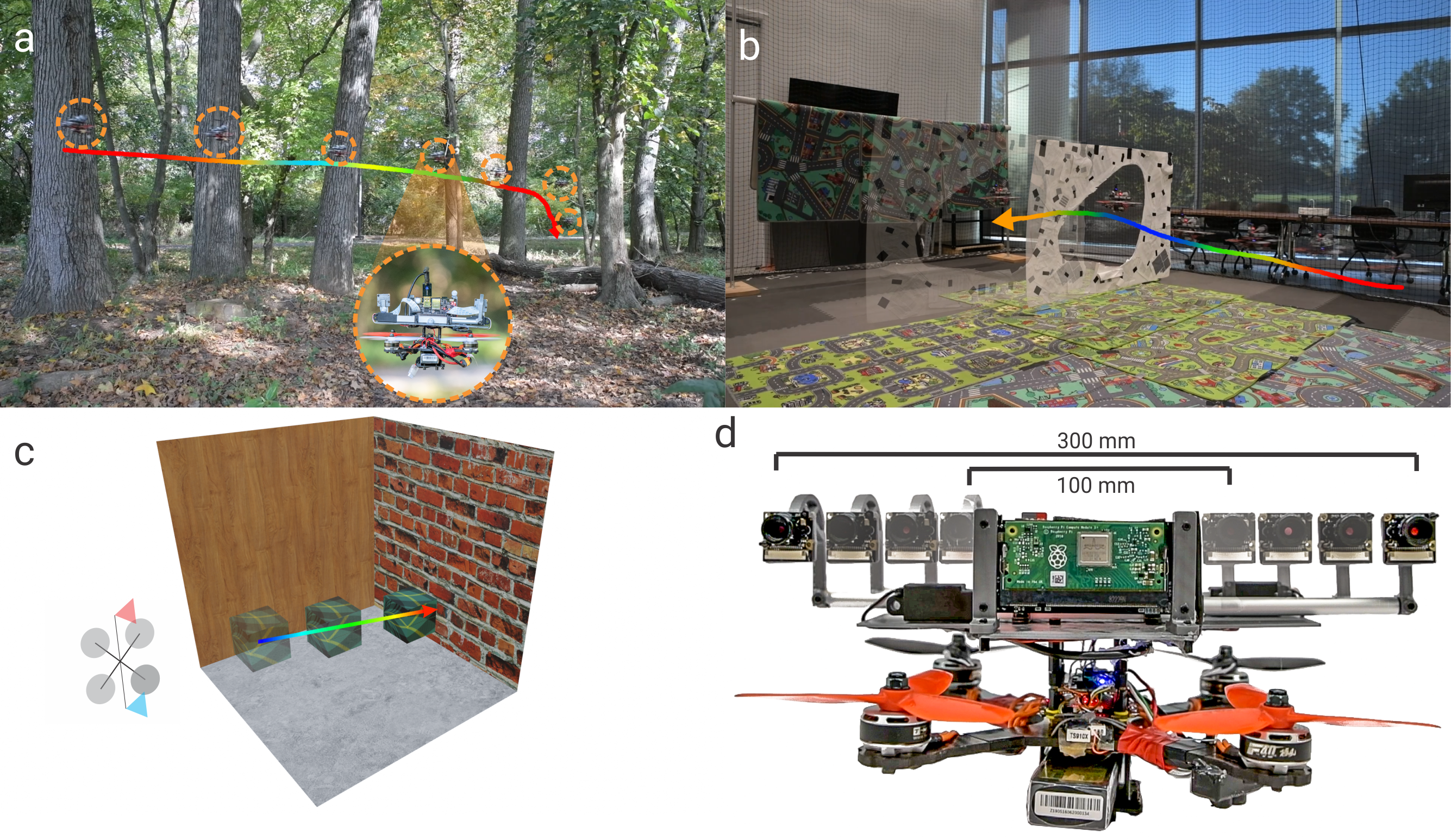
We present a framework for quadrotor navigation based on a stereo camera system whose baseline can be adapted on-the-fly. We present an extensive theoretical analysis of calibration and synchronization errors. We showcase three different applications of such a system for quadrotor navigation: (a) flying through a forest, (b) flying through an unknown shaped/location static/dynamic gap, and (c) accurate 3D pose detection of an independently moving object. We show that our variable baseline system is more accurate and robust in all three scenarios.
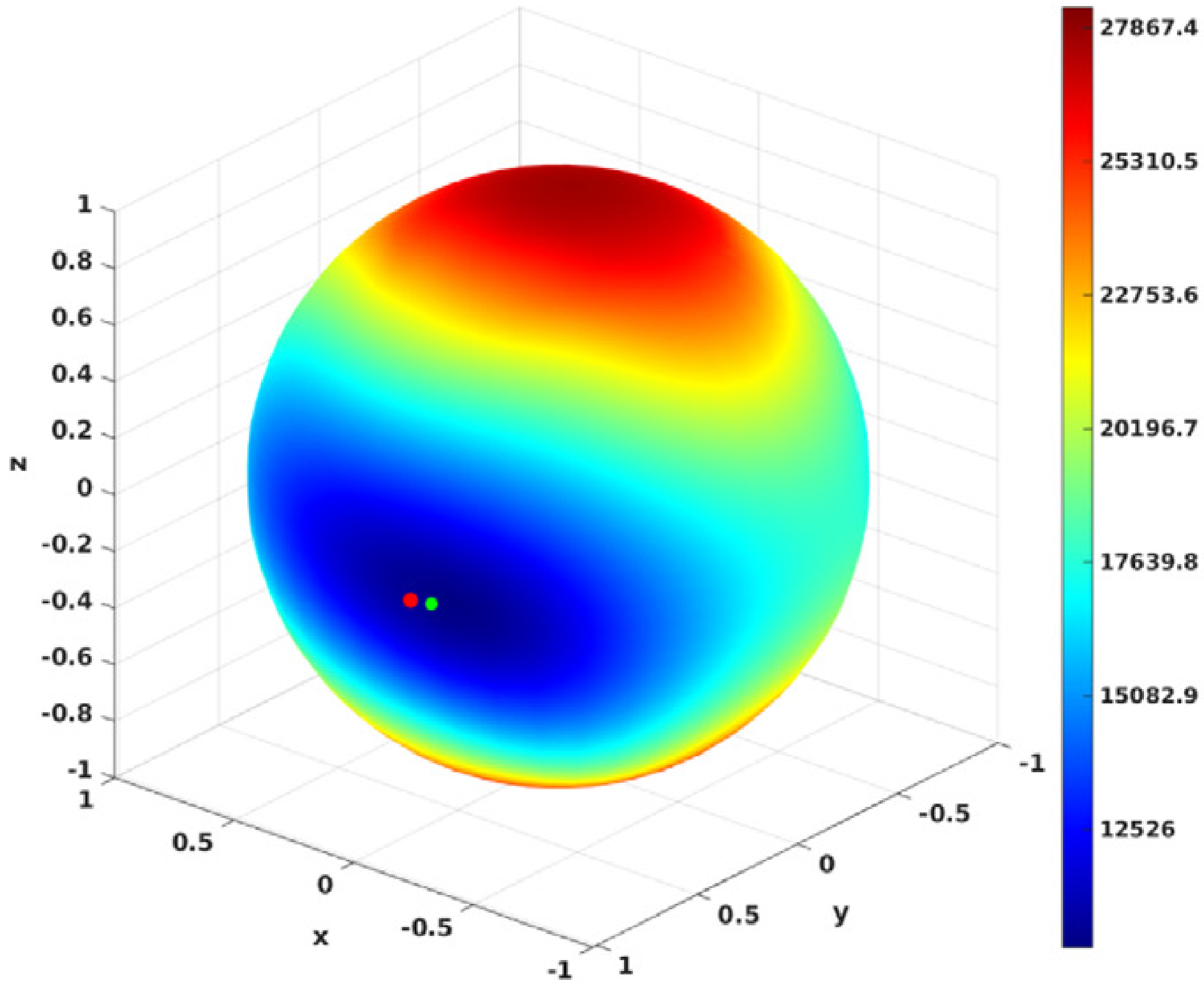
We reformulate the positive-depth constraint – the basis for estimating egomotion from normal flow – as a continuous piecewise differentiable function, which allows the use of well-known minimization techniques to solve for 3D motion. Experimental comparisons on standard synthetic datasets and the real-world driving benchmark dataset Kitti using three different optic flow algorithms show that the method achieves better accuracy in all but one case.

We introduce representations and models centered on contact, which we then use in action prediction and anticipation. We train the Anticipation Module, a module producing Contact Anticipation Maps and Next Active Object Segmentations. On top of the Anticipation Module we apply Egocentric Object Manipulation Graphs (Ego-OMG), a framework for action anticipation and prediction. Use of the Anticipation Module within Ego-OMG produces state-of-the-art results, achieving 1st and 2nd place on the unseen and seen test sets, respectively, of the EPIC Kitchens Action Anticipation Challenge, and achieving state-of-the-art results on the tasks of action anticipation and action prediction over EPIC Kitchens.
2020
This letter presents a modified robust integral of signum error (RISE) nonlinear control method, for quadrotor trajectory tracking and control. The proposed control algorithm tracks trajectories of varying speeds, uncertainties and disturbance magnitudes. To illustrate the performance of the proposed control method, comparative numerical simulation results are provided.

We propose an approach to grasp and manipulate previously unseen or zero-shot objects: the objects without any prior of their shape, size, material and weight properties, using only feedback from tactile sensors. We successfully evaluate and demonstrate our proposed approach on many real world experiments using the Shadow Dexterous Hand equipped with BioTac SP tactile sensors.

We propose a novel hybrid network, which we call Hybrid Backpropagation Parallel Echo State Network (HBP-ESN) which combines the effectiveness of learning random temporal features of reservoirs with the readout power of a deep neural network with batch normalization. We demonstrate that our new network outperforms LSTMs and GRUs on two complex real-world multi-dimensional time series datasets.
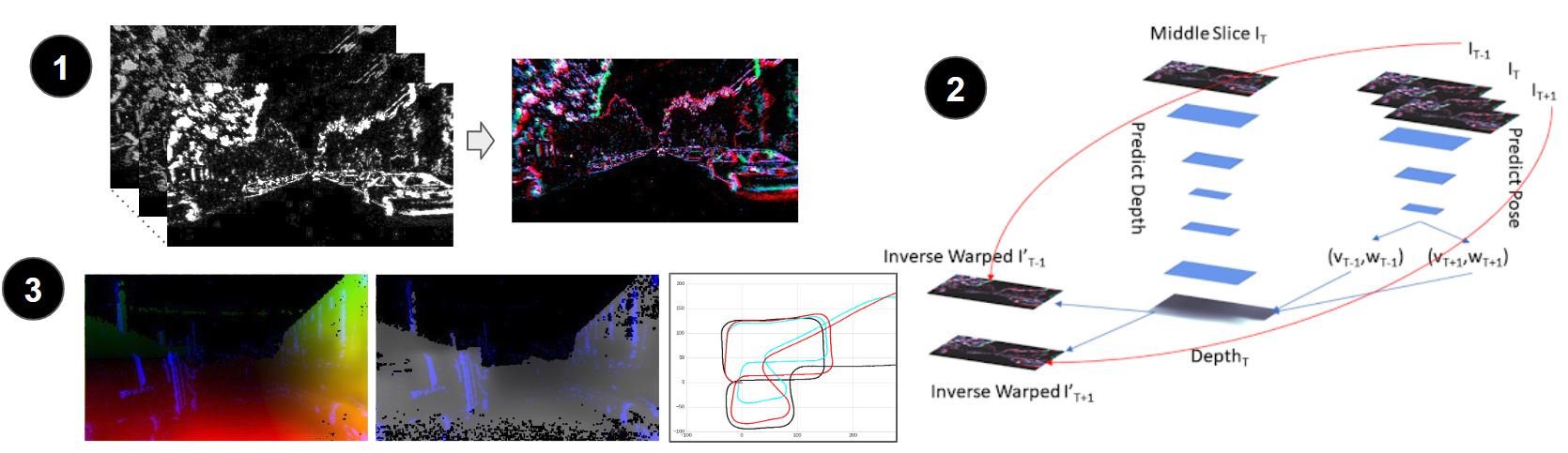
We present an unsupervised learning pipeline for dense depth, optical flow and egomotion estimation for autonomous driving applications, using the event-based output of the Dynamic Vision Sensor (DVS) as input. Our work is the first monocular pipeline that generates dense depth and optical flow from sparse event data only, and is able to transfer from day to night scenes without any additional training.
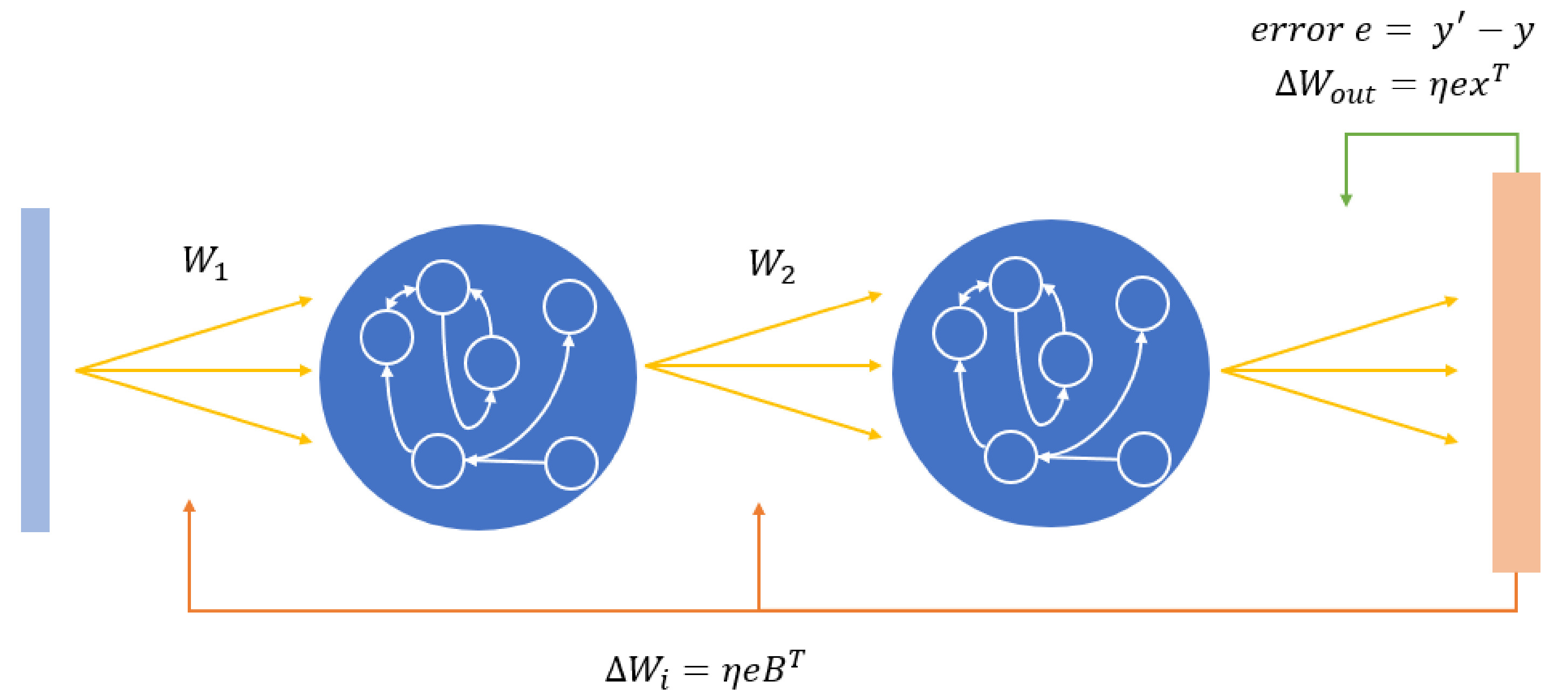
Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artificial neural networks, but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Network for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. We demonstrate its efficacy on two real world multidimensional time series datasets.
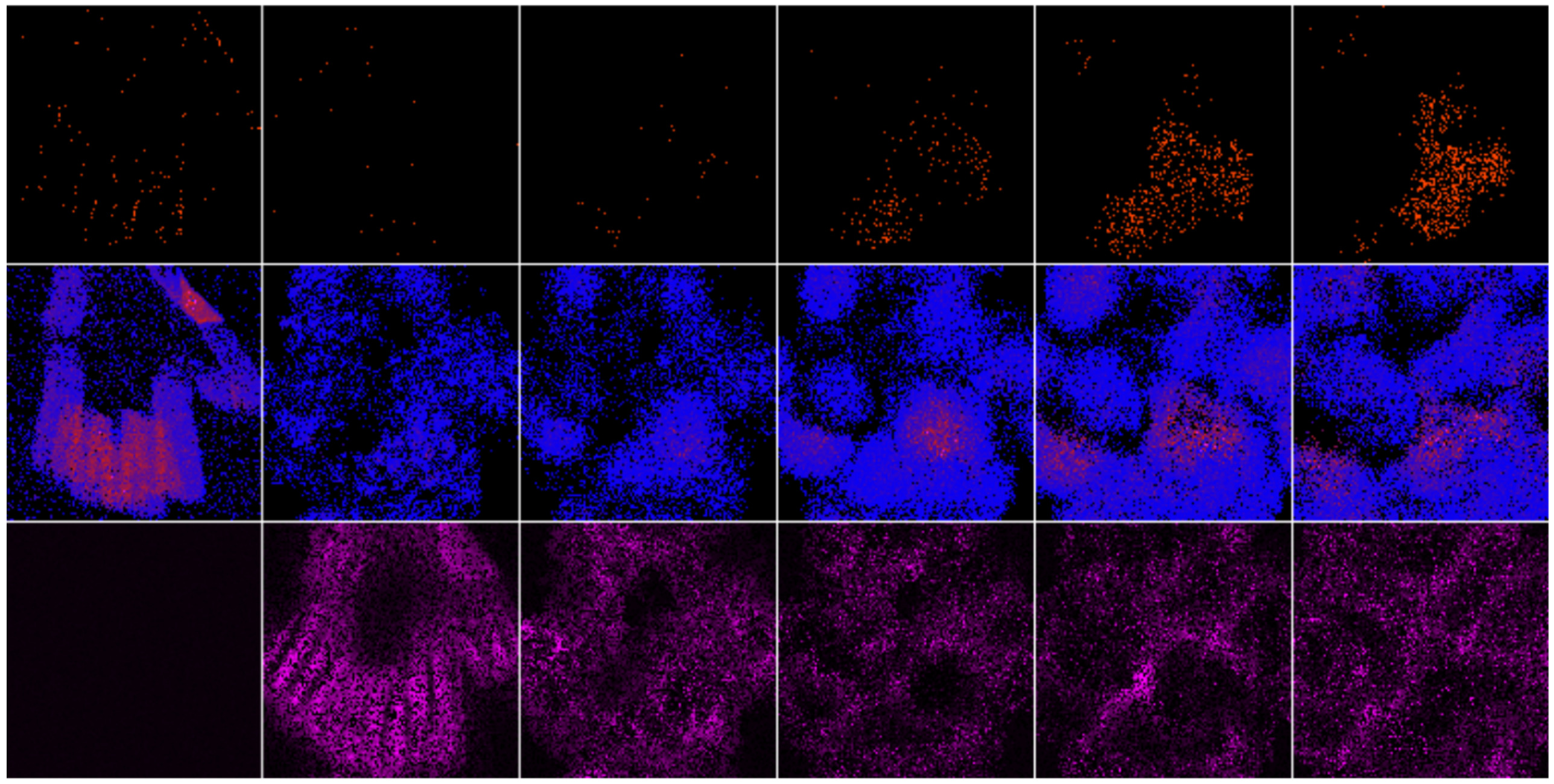
We show that a large, deep layered SNN with dynamical, chaotic activity mimicking the mammalian cortex with biologically-inspired learning rules, such as STDP, is capable of encoding information from temporal data. We argue that the randomness inherent in the network weights allow the neurons to form groups that encode the temporal data being inputted after self-organizing with STDP.
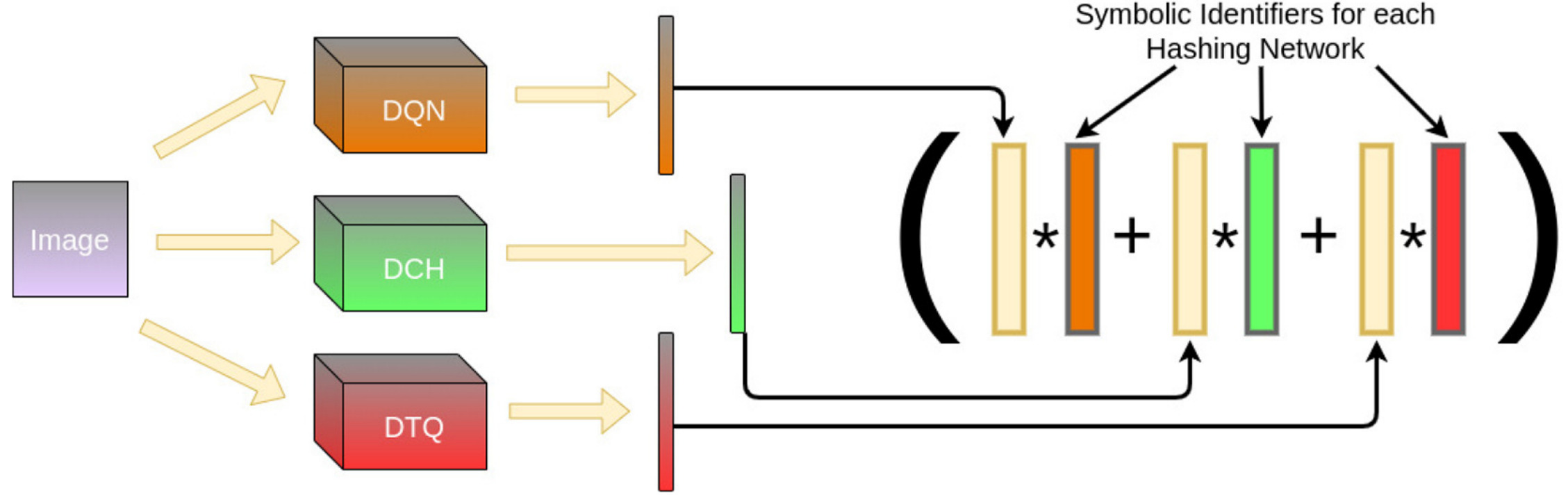
It has been proposed that machine learning techniques can benefit from symbolic representations and reasoning systems. We describe a method in which the two can be combined in a natural and direct way by use of hyperdimensional vectors and hyperdimensional computing. To the best of our knowledge, this is the first instance in which meaningful hyperdimensional representations of images are created on real data, while still maintaining hyperdimensionality.

Dynamic obstacle avoidance on quadrotors requires low latency. A class of sensors that are particularly suitable for such scenarios are event cameras. In this paper, we present a deep learning based solution for dodging multiple dynamic obstacles on a quadrotor with a single event camera and on-board computation. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with obstacles of different shapes and sizes, achieving an overall success rate of 70% including objects of unknown shape and a low light testing scenario.
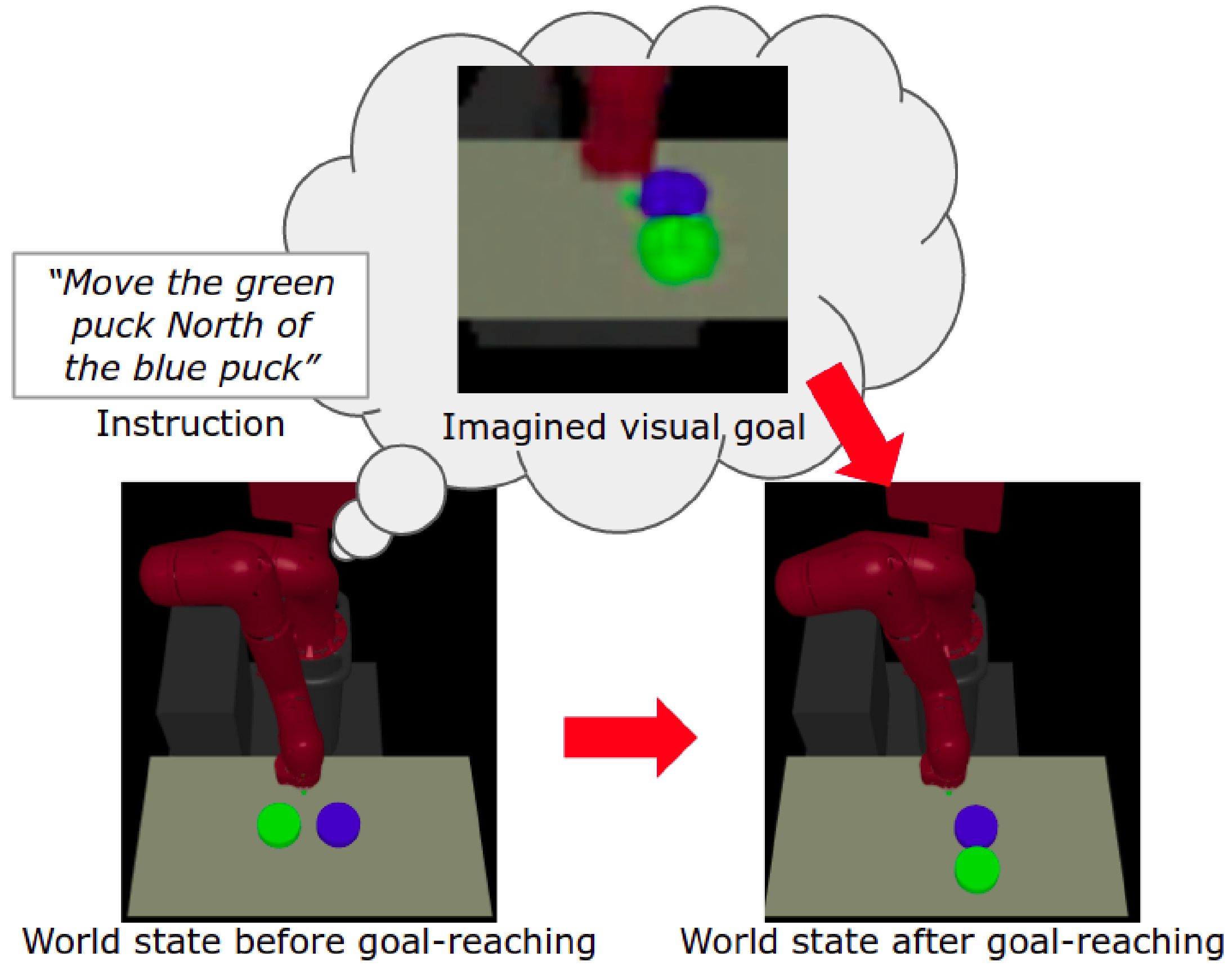
We present a novel framework for learning to perform temporally extended tasks using spatial reasoning in the RL framework, by sequentially imagining visual goals and choosing appropriate actions to fulfill imagined goals. We validate our method in two environments with a robot arm in a simulated interactive 3D environment. Our method outperforms two flat architectures with raw-pixel and ground-truth states, and a hierarchical architecture with ground-truth states on object arrangement tasks.
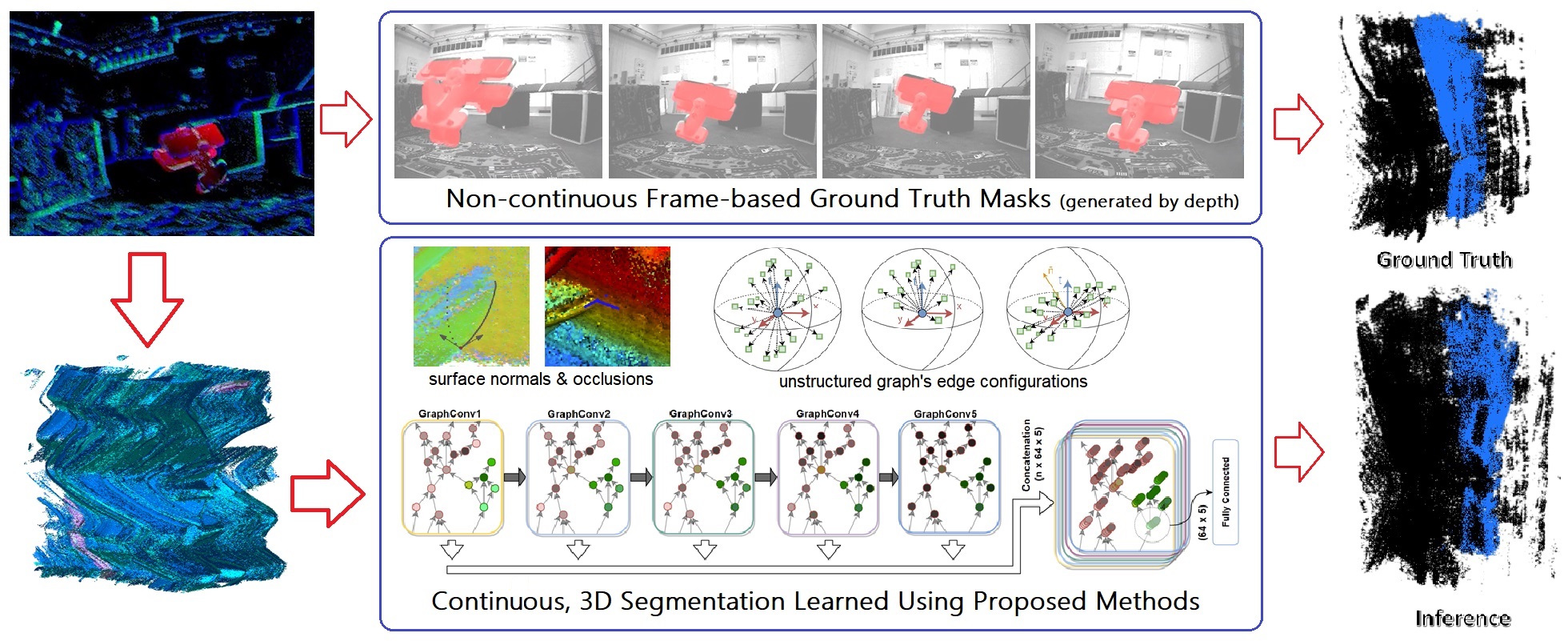
We present a Graph Convolutional neural network for the task of scene motion segmentation by a moving camera. We discuss properties of of the event data with respect to this 3D recognition problem, and show that our Graph Convolutional architecture is superior to PointNet++. We evaluate our method on the state of the art event-based motion segmentation dataset - EV-IMO and perform comparisons to a frame-based method proposed by its authors.

We present an active, bottom-up method for the detection of actor–object contacts and the extraction of moved objects and their motions in RGBD videos of manipulation actions. At the core of our approach lies non-rigid registration. We qualitatively evaluate our method on a number of input sequences and present a comprehensive robot imitation learning example, in which we demonstrate the crucial role of our outputs in developing action representations/plans from observation.
2019
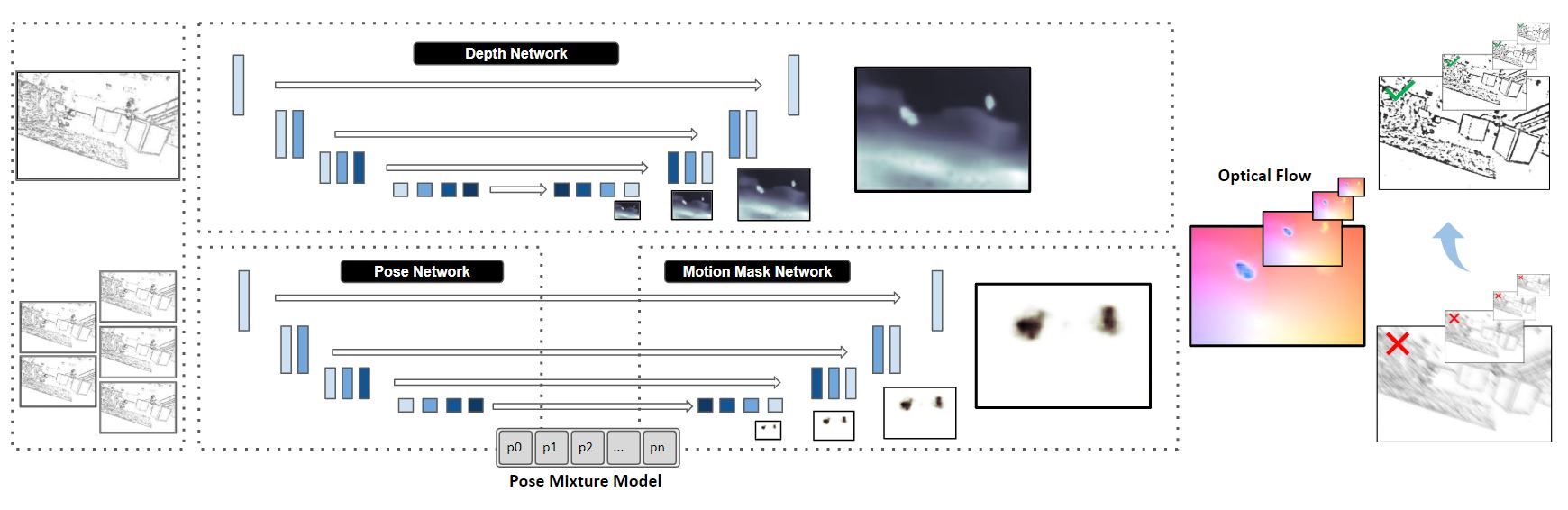
We present the first event-based learning approach for motion segmentation in indoor scenes and the first event-based dataset - EV-IMO- which includes accurate pixel-wise motion masks, egomotion and ground truth depth.We then train and evaluate our learning pipeline on EV-IMO and demonstrate that it is well suited for scene constrained robotics applications.
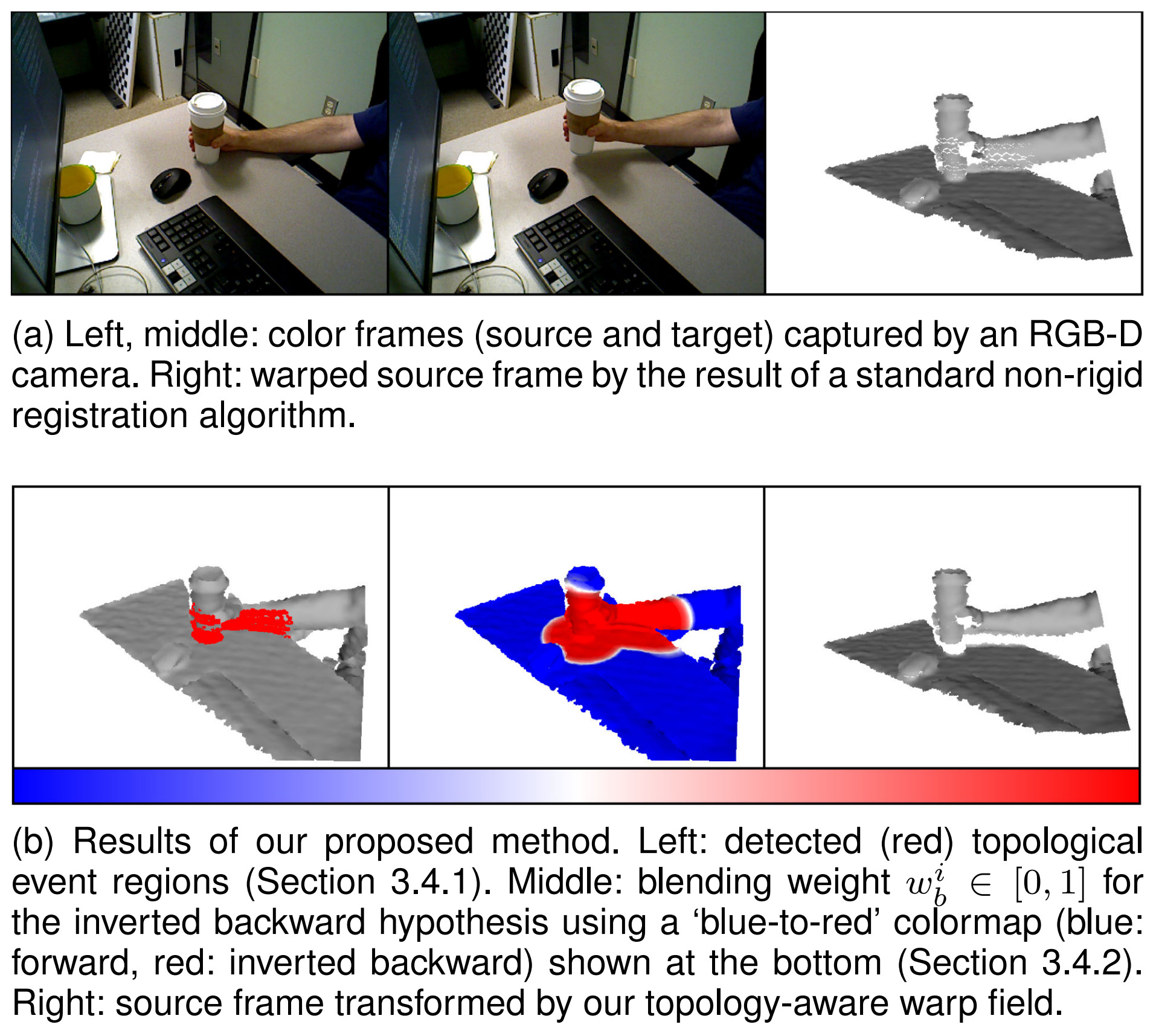
We introduce a non-rigid registration pipeline for pairs of unorganized point clouds that may be topologically different. Based on both forward and (inverted) backward warp hypotheses, we explicitly detect regions of the deformed geometry that undergo topological changes by means of local deformation criteria and broadly classify them as ‘contacts’ or ‘separations’. Subsequently, the two motion hypotheses are seamlessly blended on a local basis, according to the type and proximity of detected events. Our method achieves state-of-the-art motion estimation accuracy on the MPI Sintel dataset.

We propose network deconvolution, a procedure which optimally removes pixel-wise and channel-wise correlations before the data is fed into each layer. Filtering with such kernels results in a sparse representation, a desired property that has been missing in the training of neural networks. Learning from the sparse representation promotes faster convergence and superior results without the use of batch normalization.
We propose a method of encoding actions and perceptions together into a single space that is meaningful, semantically informed, and consistent by using hyperdimensional binary vectors (HBVs). We used DVS for visual perception and showed that the visual component can be bound with the system velocity to enable dynamic world perception, which creates an opportunity for real-time navigation and obstacle avoidance.
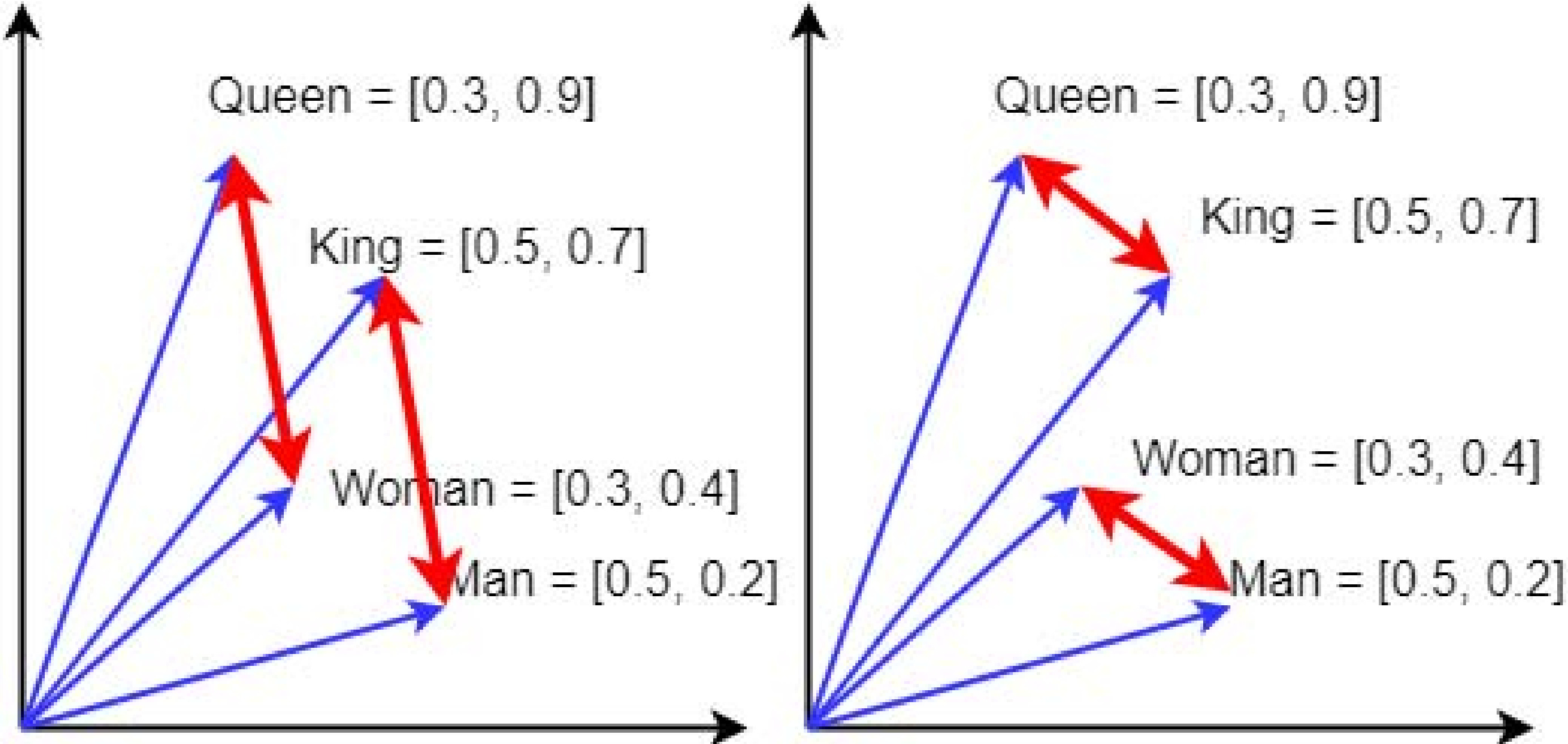
Word embeddings are commonly used to measure word-level semantic similarity in text, especially in direct word-to-word comparisons. However, the relationships between words in the embedding space are often viewed as approximately linear and concepts comprised of multiple words are a sort of linear combination. In this paper, we demonstrate that this is not generally true and show how the relationships can be better captured by leveraging the topology of the embedding space. We propose a technique for directly computing new vectors representing multiple words in a way that naturally combines them into a new, more consistent space where distance better correlates to similarity. We show that this technique works well for natural language, even when it comprises multiple words, on a simple task derived from WordNet synset descriptions and examples of words.
We present a preprocessing method to incorporate semantic information in the form of visual saliency to direct sparse odometry (DSO). We also present a framework to filter the visual saliency based on scene parsing. We provide an extensive quantitative evaluation of SalientDSO on the ICL-NUIM and the TUM monoVO data sets and show that we outperform DSO and ORB-simultaneous localization and mapping-two very popular state-of-the-art approaches in the literature. We also collect and publicly release a CVL-UMD data set which contains two indoor cluttered sequences on which we show qualitative evaluations.
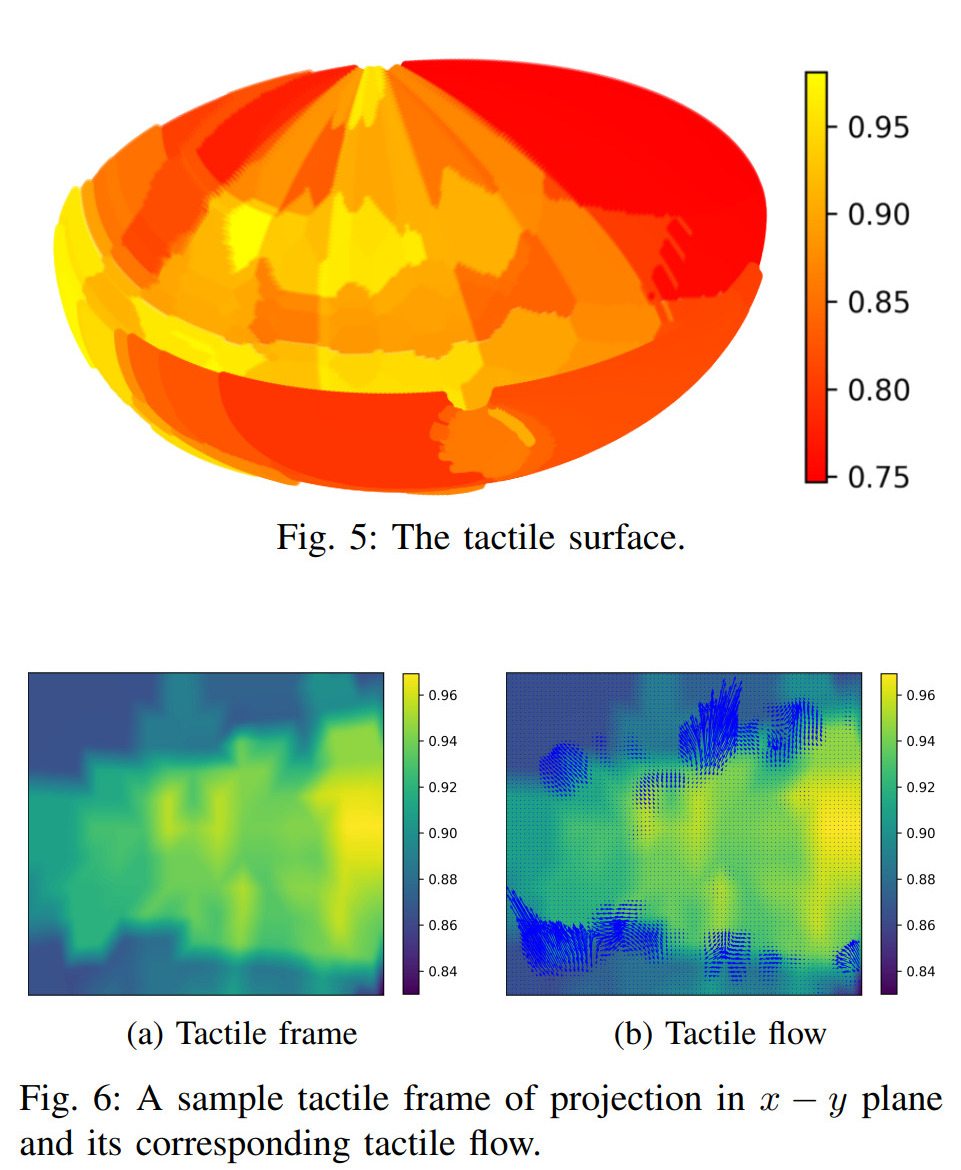
We present the computational tactile flow to improve the analysis of the tactile feedback in robots using a Shadow Dexterous Hand. In the computational tactile flow model, given a sequence of pressure values from the tactile sensors, we define a virtual surface for the pressure values and define the tactile flow as the optical flow of this surface. We provide case studies that demonstrate how the computational tactile flow maps reveal information on the direction of motion and 3D structure of the surface, and feedback regarding the action being performed by the robot.
2018

We introduce Evenly Cascaded convolutional Network (ECN), a neural network taking inspiration from the cascade algorithm of wavelet analysis. ECN produces easily interpretable features maps, a result whose intuition can be understood in the context of scale-space theory. We demonstrate that ECN's design facilitates the training process through providing easily trainable shortcuts. We report new state-of-the-art results for small networks, without the need for additional treatment such as pruning or compression - a consequence of ECN's simple structure and direct training.
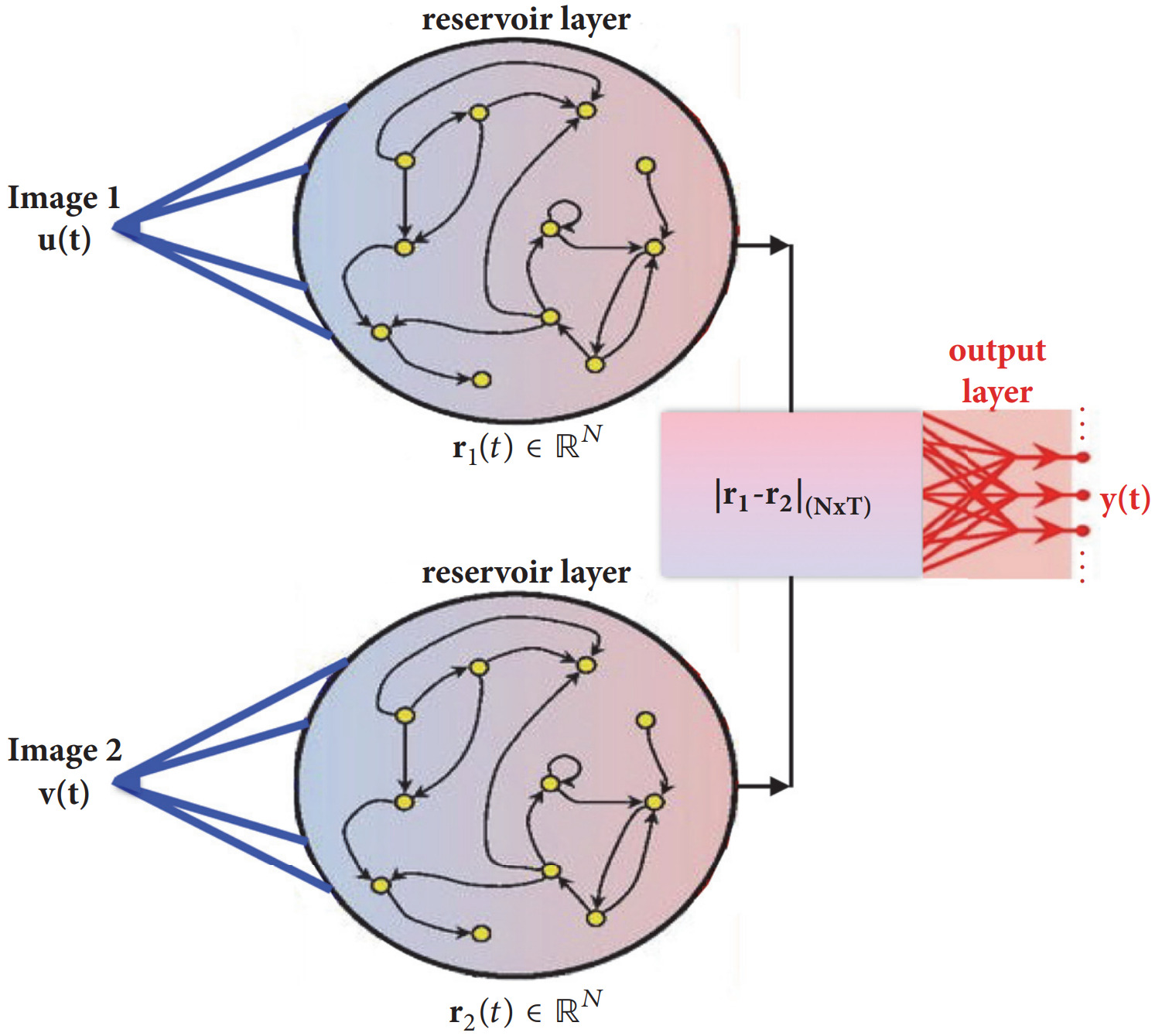
We investigate the ways in which a machine learning architecture known as Reservoir Computing learns concepts such as “similar” and “diferent” and other relationships between image pairs and generalizes these concepts to previously unseen classes of data. In generalization tasks, we observe that RCs perform signifcantly better than state-of-the-art, feed-forward, pair-based architectures such as convolutional and deep Siamese Neural Networks (SNNs). We also show that RCs can not only generalize relationships, but also generalize combinations of relationships, providing robust and efective image pair classification.

We introduce cilantro, an open-source C++ library for geometric and general-purpose point cloud data processing. The library provides functionality that covers low-level point cloud operations, spatial reasoning, various methods for point cloud segmentation and generic data clustering, flexible algorithms for robust or local geometric alignment, model fitting, as well as powerful visualization tools.

This paper presents a novel bottom-up approach for segmenting symmetric objects and recovering their symmetries from 3D pointclouds of natural scenes. Individual symmetries are used as constraints for the foreground segmentation problem that uses symmetry as a global grouping principle. Evaluation on a challenging dataset shows that our approach can reliably segment objects and extract their symmetries from incomplete 3D reconstructions of highly cluttered scenes, outperforming state-of-the-art methods by a wide margin.
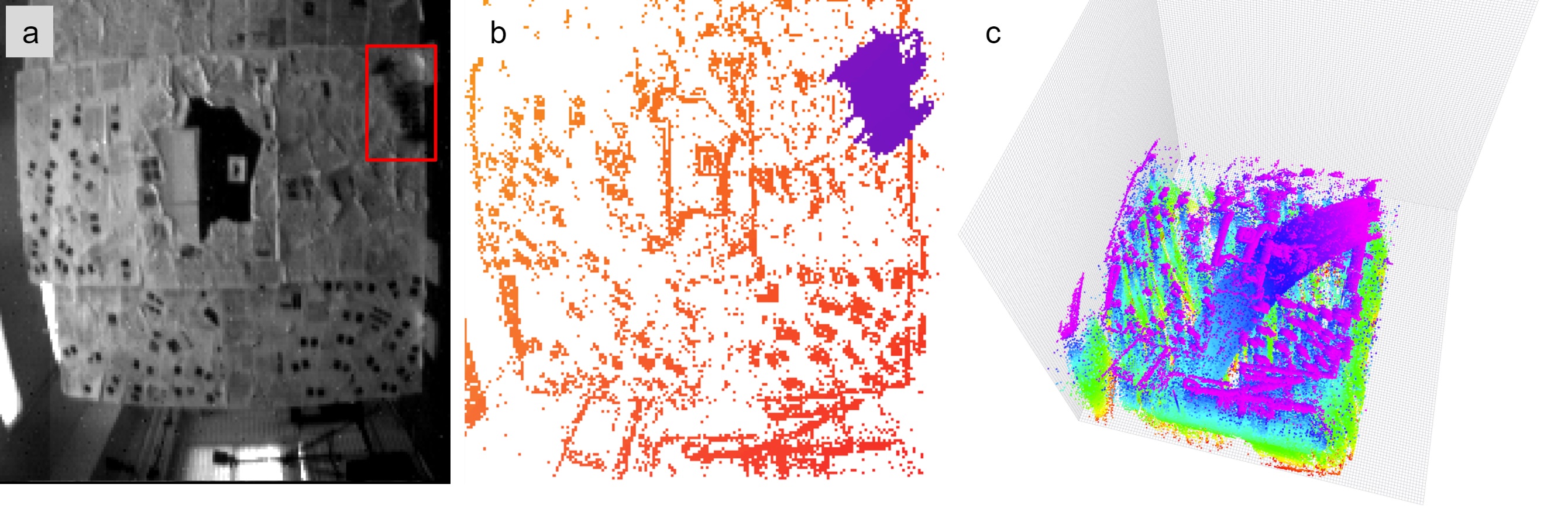
This paper presents a new, efficient approach to object tracking with asynchronous cameras. We demonstrate our framework on the task of independent motion detection and tracking, where we use the temporal model inconsistencies to locate differently moving objects in challenging situations of very fast motion.

In this work, we propose the task of solving a genre of image-puzzles (“image riddles”) that require both capabilities involving visual detection (including object, activity recognition) and, knowledge-based or commonsense reasoning. Each puzzle involves a set of images and the question “what word connects these images?”. We develop a Probabilistic Reasoning-based approach that utilizes commonsense knowledge about words and phrases to answer these riddles with a reasonable accuracy. Our approach achieves some promising results for these riddles and provides a strong baseline for future attempts.

In this letter, we propose this framework of bioinspired perceptual design for quadrotors. We use this philosophy to design a minimalist sensorimotor framework for a quadrotor to fly through unknown gaps without an explicit 3-D reconstruction of the scene using only a monocular camera and onboard sensing. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different settings and window shapes, achieving a success rate of 85% at 2.5 ms -1 even with a minimum tolerance of just 5 cm.
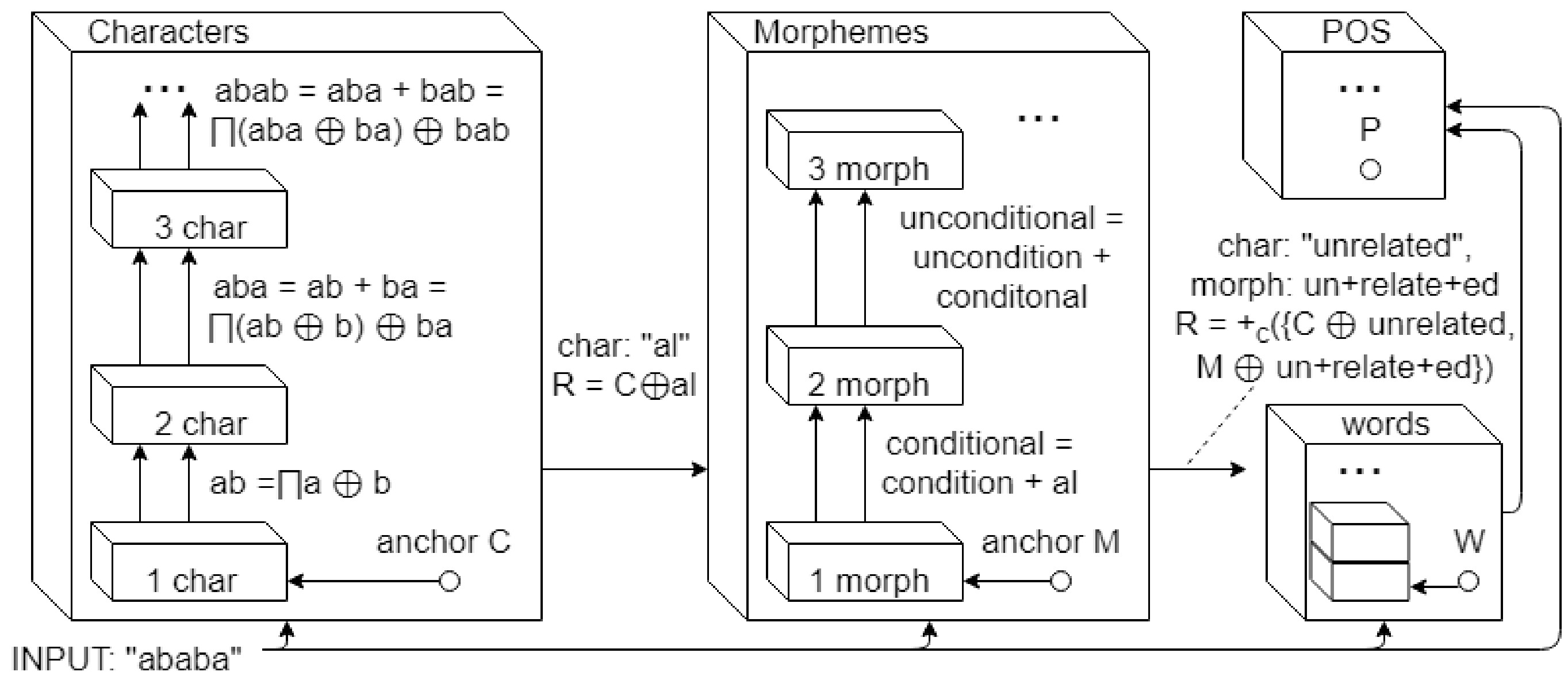
Semantic vectors are learned from data to express semantic relationships between elements of information, for the purpose of solving and informing downstream tasks. Other models exist that learn to map and classify supervised data. However, the two worlds of learning rarely interact to inform one another dynamically, whether across types of data or levels of semantics, in order to form a unified model. We explore the research problem of learning these vectors and propose a framework for learning the semantics of knowledge incrementally and online, across multiple mediums of data, via binary vectors. We discuss the aspects of this framework to spur future research on this approach and problem.
2017
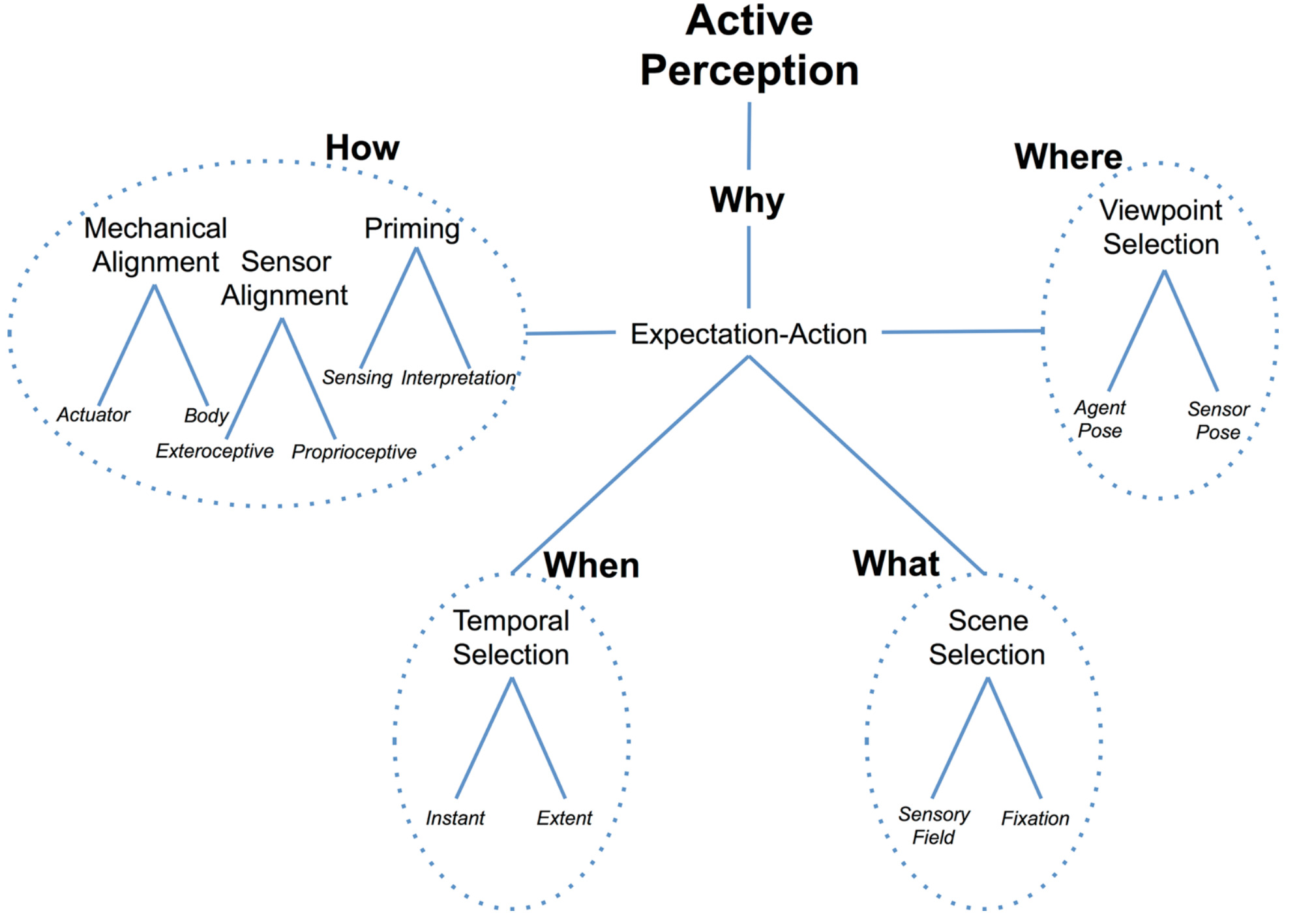
Despite the recent successes in robotics, artificial intelligence and computer vision, a complete artificial agent necessarily must include active perception. A multitude of ideas and methods for how to accomplish this have already appeared in the past, their broader utility perhaps impeded by insufficient computational power or costly hardware. The history of these ideas, perhaps selective due to our perspectives, is presented with the goal of organizing the past literature and highlighting the seminal contributions. We argue that those contributions are as relevant today as they were decades ago and, with the state of modern computational tools, are poised to find new life in the robotic perception systems of the next decade.